Deep Learning - ANN - Artificial Neural Network - Regularization Tutorial
Regularization
It is a technique to prevent the model from overfitting by adding extra information to it or adding penalty term to cost function.
What is Overfitting?
Overfitting occurs when our machine learning model tries to capture all the data points or more than the required data points of the training dataset. The overfitted model has low bias and high variance.
Overfitted model perform well in training dataset but not in test dataset.
Ways to solve Overfitting-
- Adding more data
- Add more rows
- Data Augmentation
- Reducing the complexity model
- Dropout
- Early Stopping
- Regularization(L1, L2 and a combination of L1+L2)
There are two types of regularization techniques, which are given below:
Ridge Regression (L2) [Regression]
Hyperparameter – alpha which is basically lambda
Ridge regression is one of the types of linear regression in which a small amount of bias or penalty is equivalent to the sum of the squares of the coefficients added to the loss function so that overfitting in the model gets reduced and we can get better long-term predictions.
Ridge regression is a regularization technique, which is used to reduce the complexity of the model. It is also called L2 regularization.
In this technique, the cost function is altered by adding the penalty term to it. The amount of bias added to the model is called the Ridge Regression penalty. We can calculate it by multiplying the lambda by the squared weight of each individual feature.
The equation for the cost function in ridge regression will be:
Cost Function = \(\frac{1}{n}\displaystyle\sum_{i=1}^{n} L(Y_i,Y'_i) +\lambda m^2\)
Cost Function = L + \(\frac{\lambda}{2n} \displaystyle\sum_{i=1}^{K} ||W_i||^2\) = L + \(\frac{\lambda}{2n}[W^2_1 + W^2_2 + ....+ W^2_K]\)
\(\lambda\) = hyperparamter i.e is alpha
In the above equation, the penalty term m2 regularizes the coefficients of the model, and hence ridge regression reduces the amplitudes of the coefficients by decreasing the complexity of the model.
For example-

For the overfitted model, Loss LN( Linear Regression) > Loss LR (Ridge Regression).
Hence, we will select the Loss LR model over Loss LN.
In the linear Regression Line, due to overfitting, Loss is equal to zero. Hence to reduce overfitting, we will add a penalty term, which will increase the bias but reduce variance, to adjust the bias variance trade-off.
5 Key Points – Ridge Regression
- How does the coefficient get affected?
The coefficient will shrink toward 0, but not become 0, whenever the lambda increases.
- Higher values are impacted more by increasing lambda values.
A coefficient with a high value is impacted more as compared to a coefficient with less value on increasing lambda value.
- Bias Variance TradeOff
Bias and variance depend on the lambda value
Lambda(decrease) - Bias(decrease) overfit Variance (increase)
Lambda(increase) - Bias(increase) underfit Variance (decrease)
Impact on the Loss Function
Increasing the lambda function will shrink the loss function to 0.
Why called Ridge?
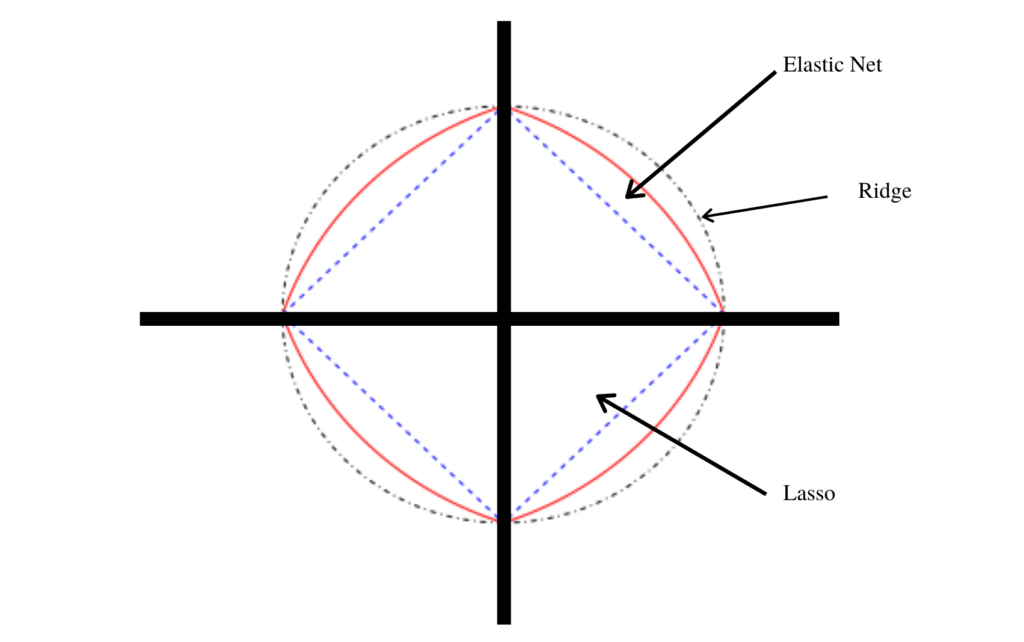
Because the solution lies on a circle perimeter .i.e on the ridge, it is called a ridge.
Practical Tips
Apply ridge regression only when there input field is greater than or equal to 2
Lasso Regression (L1) [Regression]
Hyperparameter – alpha which is basically lambda
Lasso regression is another regularization technique to reduce the overfitting OR complexity of the model. It stands for Least Absolute Shrinkage and Selection Operator.
It is similar to the Ridge Regression except that the penalty term contains only the absolute values of coefficients instead of a square of coefficients.
Since it takes absolute values, hence, it can shrink the slope to 0, whereas Ridge Regression can only shrink it near to 0.
Due to this, we can perform feature selection in lasso regression. Hence, the lasso is better in terms of Ridge.
It is also called L1 regularization. The equation for the cost function of Lasso regression will be:
Cost Function = \(\frac{1}{n}\displaystyle\sum_{i=1}^{n} L(Y_i,Y'_i) +\lambda m\)
Cost Function = L + \(\frac{\lambda}{2n} \displaystyle\sum_{i=1}^{K} ||W_i||\) = L + \(\frac{\lambda}{2n}[W_1 + W_2 + ....+ W_K]\)
\(\lambda\) = hyperparamter i.e is alpha
Cost Function = \(\displaystyle\sum_{i=1}^{n} L(Y_i,Y'_i) +\displaystyle\sum_{l=1}^{L}\sum_{i=1}\sum_{j=1}||W^l_{ij}||^2\)
Some of the features in this technique are completely neglected for model evaluation.
Hence, the Lasso regression can help us to reduce the overfitting in the model as well as the feature selection.
Why does Lasso regression create sparsity?
In Ridge Regression, on increasing lambda value Coefficient will shrink toward 0, but not become 0. But in the case of Lasso, it will shrink to 0.
In ridge, the value of lambda is in the denominator in the coefficient formula, hence lambda can’t affect the numerator to shrink the coefficient value to zero.
In the case of the lasso, the value of lambda is in the numerator in the coefficient formula, hence lambda can affect the numerator to shrink the coefficient value to zero.
This means that variables are removed from the model, hence the sparsity.
Elastic Net [Regression]
Hyperparameter – alpha which is basically lambda, l1_ratio which will decide the weightage of lasso and ridge
Elastic net linear regression uses the penalties from both the lasso and ridge techniques to regularize regression models. The technique combines both the lasso and ridge regression methods by learning from their shortcomings to improve the regularization of statistical models
The elastic net method performs variable selection and regularization simultaneously.
The elastic net technique is most appropriate where the dimensional data is greater than the number of samples used.
Groupings and variable selection are the key roles of the elastic net technique.
The L1 Ratio will decide the weightage of Ridge and Lasso. If L1 Ratio =0.9, then 0.9% ridge and 0.1% lasso. Alpha(lambda) = a+b

When to use an elastic net?
- When you are unsure about whether to use a lasso or ridge
- If the input column has multicollinearity, then the elastic net is perfect.
What is Weight Decay?
Weight decay is a regularization technique in deep learning. Weight decay works by adding a penalty term to the cost function of a neural network which has the effect of shrinking the weights during backpropagation. This helps prevent the network from overfitting the training data as well as the exploding gradient problem.
L' = L + \(\frac{\lambda}{2}\displaystyle\sum||W_i||^2\)
\(\frac{\delta L'}{\delta W_0} = \frac{\delta L}{\delta W_0} + \frac{\lambda}{2}2W_0\)
=\(\frac{\delta L}{\delta W_0} + \lambda{W_0}\)
\(W_n = W_0 - \eta(\frac{\delta L}{\delta W_0}+ \lambda{W_0})\)
\(W_n = W_0 - \eta\frac{\delta L}{\delta W_0}- \eta\lambda{W_0}\)
\(W_n = W_0 (1-\eta\lambda) - \eta\frac{\delta L}{\delta W_0}\)
Weight Decay = \((1-\eta\lambda) \)