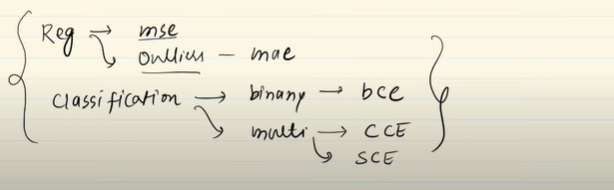Deep Learning - ANN - Artificial Neural Network - Loss Function Tutorial
Loss Function-
The loss function is a method of evaluating how well your algorithm is modeling your dataset.
If your loss function value is high, then basically loss function is performing poorly. If your loss function value is low, then basically loss function is performing great.
Loss Function in Deep Learning- (Please check in Machine Learning Notes)
1] Regression
- Mean Squared Error
- Mean Absolute Error
- Huber Loss
2] Classification
- Binary Cross Entropy
- Categorical Cross Entropy
- Hinge Loss
3] Autoencoders
- KL Divergence
4] GAN
- Discriminator Loss
- Min Max GAN Loss
5] Object Detection
- Focal Loss
6] Embedding
- Triplet Loss
Loss Function(Error Function) VS Cost Function
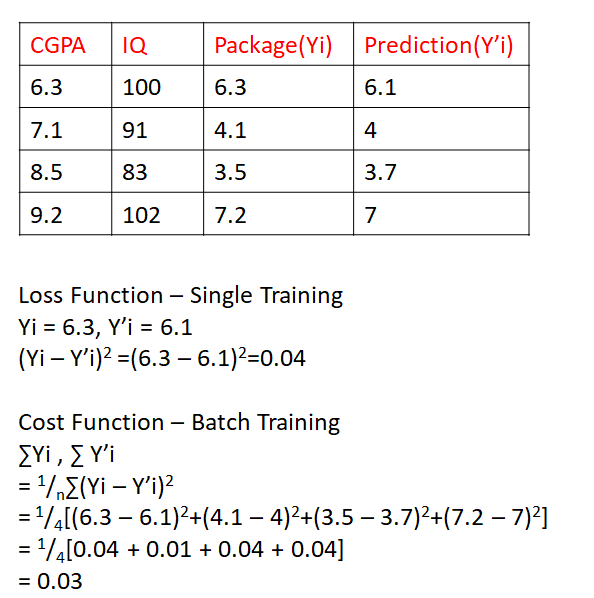
1] Regression
a) MSE- Mean Square error(if no outlier)
Advantages-
- Easy to Interpret
- Differentiable ( Gradient Descent )
- 1 Local Minima
Disadvantages-
- Error Unit (Squared) is different
- Not Robust to Outliers
b) MAE – Mean Absolute Error (if outlier)
Advantages-
- Intuitive and easy
- Unit same
- Robust to Outlier
Disadvantages-
- Not Differentiable
c) Huber Loss – if 25% point is an outlier
\(L= \begin{cases} \frac{1}{2} (Y - Y')^2 & \quad \text{for |Y - Y'| <= }\delta\\ \delta|Y - Y'| - \frac{1}{2}\delta^2 & \quad \text{otherwise} \end{cases} \)
If data has an outlier, then Huber loss will act as a Mean Absolute Error.
If not, then it acts as a Mean Squared Error.
1] Classification
a) BCE - Binary Cross Entropy (if 2 classes)
Used in classification and has only two classes.
Loss Function = -Y log(Y') - (1 - Y) log(1 - Y')
Y -> Actual Value/Target
Y' -> Predicted Value
The activation function can only be Sigmoid of Output.
Cost Function = \(-\frac{1}{n}[ \displaystyle\sum_{i=1}^{n}(Y_i log(Y_i') + (1 - Y_i) log(1 - Y_i'))]\)
Advantages-
- Differentiable
Disadvantages-
- Multi Local Minima
- Intuitive
b) CCE – Categorical Cross Entropy( if more than 2 class)
used in Softmax Regression and Multi-Class Classification
Cost Function = \(- \displaystyle\sum_{j=1}^{k}(Y_j log(Y_j')\)
where k is # classes in the data
SCE – Sparse Cross Entropy( if more than 2 class)