Deep Learning - ANN - Artificial Neural Network - Backward Propagation Tutorial
What is BackPropagation?
It is an algorithm to train neural networks. It is the method of fine-tuning the weights of a neural network based on the error rate obtained in the previous epoch (i.e., iteration).
Backpropagation, short for "backward propagation of errors," is an algorithm for supervised learning of artificial neural networks using gradient descent. Given an artificial neural network and an error function, the method calculates the gradient of the error function with respect to the neural network's weights using the chain rule.
Prerequisite-
- Gradient Descent
- Forward Propagation
Let's take a small example-
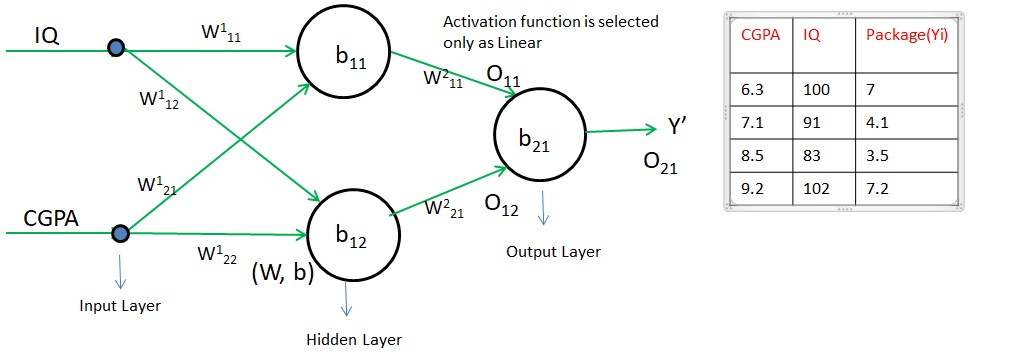
Step 0] Initialize w and b with random values i.e w = 1, b = 0
Step 1] Select any point(row from the student table). Let say CGPA = 6.3 and IQ = 100
Step 2] Predict(LPA) using forward propagation.
Let's say the predicted value is 18 and the actual value is 7. which means there is an error, it is because the value of w and b is incorrect(random)
Step 3] Choose a loss function to reduce error. We will select MSE since it is a regression case i.e. L = (Y – Y’)2 = (7 – 18)2 = 121 is the error for the 1st student.
Based on the error rate we have to adjust L’ (we can’t change L as it is actual data). To change L’ we need to adjust w and b. So the error will be minimal.
Y’ i.e O21 = W211 O11 + W221 O12 + b21
O11 = W111 IQ + W121 CGPA + b11
O12 = W112 IQ + W122 CGPA + b12
As we are going in backward direction i.e
from O21 to ‘O11 and O12 ‘ and
from (O11 to ‘W111 , W121 and b11’ and O12 to ‘W112, W122 and b12’) respectively
And there we need to make changes in w and b to reduce loss. Therefore it is called BackPropagation.
Step 4] Weight and bias need to be updated based on Gradient Descent.
\(W_{new} = W_{old} - \eta\frac{\delta L}{\delta W_{old}}\)
\(b_{new} = b_{old} - \eta\frac{\delta L}{\delta b_{old}}\)
As O21 depend on W211, W221, b21, O11 and O12
Therefore to update O21, we need to update W211 as, \(W^2_{11new} = W^2_{11old} - \eta\frac{\delta L}{\delta W^2_{11}}\)to update W221 as \(W^2_{21new} = W^2_{21old} - \eta\frac{\delta L}{\delta W^2_{21}}\) and to update b21 a \(b_{21new} = b_{21old} - \eta\frac{\delta L}{\delta b_{21}}\)
we already have Wold = 1 taken in step 0] \(\eta - \text{value is 0.01}\) and we only need to find \(\frac{\delta L}{\delta W^2_{11}}\) i.e derivative of loss with respect to weight
In the above image, there is 9 weight and bias. Hence, we need to calculate the derivative of Loss with respect to each weight and bias using the chain rule of differentiation.
\([\frac{\delta L}{\delta W^2_{11}}, \frac{\delta L}{\delta W^2_{21}},\frac{\delta L}{\delta b_{21}}],[\frac{\delta L}{\delta W^1_{11}},\frac{\delta L}{\delta W^1_{21}},\frac{\delta L}{\delta b_{11}}],[\frac{\delta L}{\delta W^1_{12}},\frac{\delta L}{\delta W^1_{22}},\frac{\delta L}{\delta b_{12}}]\)
what is dy/dy - when we make any changes in x, then how much amount of changes will happen in y
Let's try to find out the derivative of L with respect to W211 -
\(\frac{\delta L}{\delta W^2_{11}} = \frac{\delta L}{\delta Y'} \times \frac{\delta Y'}{\delta W^2_{11}}\) - Chain rule of differentiation(i.e on changing W211 how much Y' will change and on changing Y' how much L will change)
\(\frac{\delta L}{\delta Y'} = \frac{\delta (Y - Y')^2}{\delta Y'} = -2 (Y - Y')\)
\(\frac{\delta Y'}{\delta W^2_{11}} = \frac{\delta [O_{11}W^2_{11} + O_{12}W^2_{21} + b_{21}]}{\delta W^2_{11}} = O_{11}\)
\(\frac{\delta L}{\delta W^2_{11}} = -2(Y-Y')O_{11}\)
Let's try to find out the derivative of L with respect to W221 -
\(\frac{\delta L}{\delta W^2_{21}} = \frac{\delta L}{\delta Y'} \times \frac{\delta Y'}{\delta W^2_{21}}\)
\(\frac{\delta L}{\delta Y'} = \frac{\delta (Y - Y')^2}{\delta Y'} = -2 (Y - Y')\)
\(\frac{\delta Y'}{\delta W^2_{21}} = \frac{\delta [O_{11}W^2_{11} + O_{12}W^2_{21} + b_{21}]}{\delta W^2_{21}} = O_{12}\)
\(\frac{\delta L}{\delta W^2_{21}} = -2(Y-Y')O_{12}\)
Let's try to find out the derivative of L with respect to b21 -
\(\frac{\delta L}{\delta b_{21}} = \frac{\delta L}{\delta Y'} \times \frac{\delta Y'}{\delta b_{21}}\)
\(\frac{\delta L}{\delta Y'} = \frac{\delta (Y - Y')^2}{\delta Y'} = -2 (Y - Y')\)
\(\frac{\delta Y'}{\delta b_{21}} = \frac{\delta [O_{11}W^2_{11} + O_{12}W^2_{21} + b_{21}]}{\delta b_{21}} = 1\)
\(\frac{\delta L}{\delta b_{21}} = -2(Y-Y')\)
Similarly, we can find other remaining 6 derivatives like this-
\(\frac{\delta L}{\delta W^1_{11}} = \frac{\delta L}{\delta Y'} \times \frac{\delta Y'}{\delta O_{11}}\times \frac{\delta O_{11}}{\delta W^1_{11}}\)
\(\frac{\delta L}{\delta W^1_{21}} = \frac{\delta L}{\delta Y'} \times \frac{\delta Y'}{\delta O_{11}}\times \frac{\delta O_{11}}{\delta W^1_{21}}\)
\(\frac{\delta L}{\delta b_{11}} = \frac{\delta L}{\delta Y'} \times \frac{\delta Y'}{\delta O_{11}}\times \frac{\delta O_{11}}{\delta b_{11}}\)
\(\frac{\delta L}{\delta W^1_{12}} = \frac{\delta L}{\delta Y'} \times \frac{\delta Y'}{\delta O_{12}}\times \frac{\delta O_{12}}{\delta W^1_{12}}\)
\(\frac{\delta L}{\delta W^1_{22}} = \frac{\delta L}{\delta Y'} \times \frac{\delta Y'}{\delta O_{12}}\times \frac{\delta O_{12}}{\delta W^1_{22}}\)
\(\frac{\delta L}{\delta b_{12}} = \frac{\delta L}{\delta Y'} \times \frac{\delta Y'}{\delta O_{12}}\times \frac{\delta O_{12}}{\delta b_{12}}\)
\(\frac{\delta Y'}{\delta O_{11}} = \frac{\delta [W^2_{11}O_{11} + W^2_{21} O_{21}+ b_{21}]}{\delta O_{11}} = W^2_{11}\)
\(\frac{\delta Y'}{\delta O_{12}} = \frac{\delta [W^2_{11}O_{11} + W^2_{21} O_{21}+ b_{21}]}{\delta O_{12}} = W^2_{21}\)
\(\frac{\delta O_{11}}{\delta W^1_{11}} = \frac{\delta [IQ.W^1_{11} + CGPA.W^1_{21} + b_{11}]}{\delta W^1_{11}} = IQ\) let's say it is a Xi1
\(\frac{\delta O_{11}}{\delta W^1_{21}} \) let's say it is a Xi2
\(\frac{\delta O_{11}}{\delta b_{21}} \) = 1
\(\frac{\delta O_{11}}{\delta W^1_{12}} = \frac{\delta [IQ.W^1_{12} + CGPA.W^1_{22} + b_{12}]}{\delta W^1_{12}} = IQ\) let's say it is a Xi1
\(\frac{\delta O_{12}}{\delta W^1_{22}} \) let's say it is a Xi2
\(\frac{\delta O_{12}}{\delta b_{12}} \) = 1
Therefore,
\(\frac{\delta L}{\delta W^1_{11}} = \frac{\delta L}{\delta Y'} \times \frac{\delta Y'}{\delta O_{11}}\times \frac{\delta O_{11}}{\delta W^1_{11}}\) = -2(Y - Y') W211 Xi1
\(\frac{\delta L}{\delta W^1_{21}} = \frac{\delta L}{\delta Y'} \times \frac{\delta Y'}{\delta O_{11}}\times \frac{\delta O_{11}}{\delta W^1_{21}}\) = -2(Y - Y') W211 Xi2
\(\frac{\delta L}{\delta b_{11}} = \frac{\delta L}{\delta Y'} \times \frac{\delta Y'}{\delta O_{11}}\times \frac{\delta O_{11}}{\delta b_{11}}\) = -2(Y - Y') W211
\(\frac{\delta L}{\delta W^1_{12}} = \frac{\delta L}{\delta Y'} \times \frac{\delta Y'}{\delta O_{12}}\times \frac{\delta O_{12}}{\delta W^1_{12}}\) = -2(Y - Y') W221 Xi1
\(\frac{\delta L}{\delta W^1_{22}} = \frac{\delta L}{\delta Y'} \times \frac{\delta Y'}{\delta O_{12}}\times \frac{\delta O_{12}}{\delta W^1_{22}}\) = -2(Y - Y') W221 Xi2
\(\frac{\delta L}{\delta b_{12}} = \frac{\delta L}{\delta Y'} \times \frac{\delta Y'}{\delta O_{12}}\times \frac{\delta O_{12}}{\delta b_{12}}\) = -2(Y - Y') W221
Summarizing Back Propagation Algorithm
epochs = 5
for i in range(epochs):
for j in range(X, Shape[0]):
-> Select 1 row(random)
-> Predict using forward propagation
-> Calculate loss using loss function - MSE
-> Update weights and bias using Gradient Descent
\(W_{new} = W_{old} - \eta\frac{\delta L}{\delta W_{old}}\)
-> Calculate the average loss for the epoch
\(\frac{\delta L}{\delta W^2_{21}} \) = -2(Y - Y') O11
\(\frac{\delta L}{\delta W^2_{21}}\) = -2(Y - Y') O12
\(\frac{\delta L}{\delta b_{21}}\) = -2(Y - Y')
\(\frac{\delta L}{\delta W^1_{11}} \) = -2(Y - Y') W211 Xi1
\(\frac{\delta L}{\delta W^1_{21}}\) = -2(Y - Y') W211 Xi2
\(\frac{\delta L}{\delta b_{11}}\) = -2(Y - Y') W211
\(\frac{\delta L}{\delta W^1_{12}}\) = -2(Y - Y') W221 Xi1
\(\frac{\delta L}{\delta W^1_{22}}\) = -2(Y - Y') W221 Xi2
\(\frac{\delta L}{\delta b_{12}}\) = -2(Y - Y') W221
BackPropagation Regression Practical
Classification Example
We will use the Activation Function as the Sigmoid Function and the loss function as Binary Cross Entropy. Rest all process will be same as Regression
BackPropagation Classification Practical
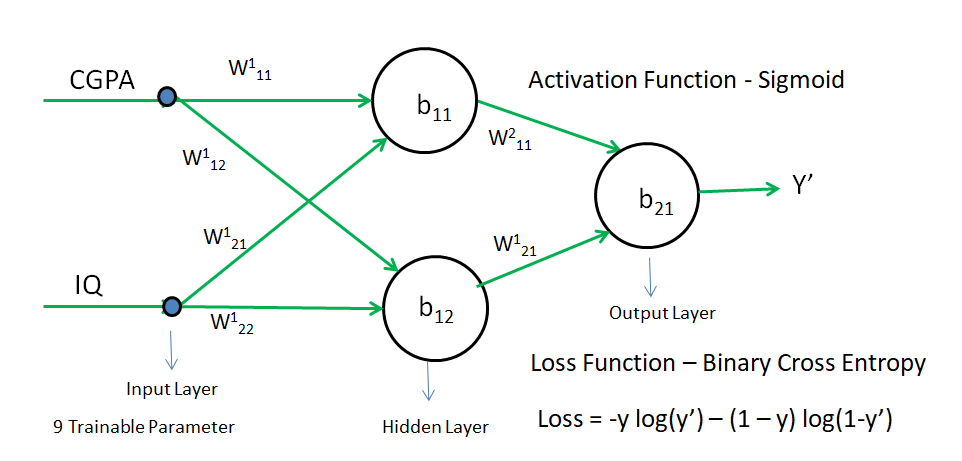
Z = W111 x CGPA + W121 x IQ + b11
Addition step in case of classification - we need to pass the Z in sigma(sigmoid function) i.e \(\sigma(Z) = O_{11}\) to get the final Output
In the above image, there is 9 weight and bias. Hence, we need to calculate the derivative of Loss with respect to each weight and bias using the chain rule of differentiation.
\([\frac{\delta L}{\delta W^2_{11}}, \frac{\delta L}{\delta W^2_{21}},\frac{\delta L}{\delta b_{21}}],[\frac{\delta L}{\delta W^1_{11}},\frac{\delta L}{\delta W^1_{21}},\frac{\delta L}{\delta b_{11}}],[\frac{\delta L}{\delta W^1_{12}},\frac{\delta L}{\delta W^1_{22}},\frac{\delta L}{\delta b_{12}}]\)
what is dy/dy - when we make any changes in x, then how much amount of changes will happen in y
L = -y log(y') - (1 - y) log(1 - y')
Let's try to find out the derivative of L with respect to W211 -
\(\frac{\delta L}{\delta W^2_{11}} = \frac{\delta L}{\delta Y'} \times \frac{\delta Y'}{\delta Z} \times \frac{\delta Z}{\delta W^2_{11}}\) - Chain rule of differentiation(i.e on changing W211 how much Z will change and on changing Z how much Y' will change and on changing Y' how much L will change)
\(\frac{\delta L}{\delta Y'} = \frac{\delta [\text{-y log(y') - (1-y) log(1-y)}]}{\delta Y'} \)
\(=\frac{-y}{y'} + \frac{1-y}{1-y'} = \frac{-y(1-y') + y'(1-y)}{y'(1-y')}\)
\(= \frac{-y+yy' + y'-yy'}{y'(1-y')} = \frac{-(y-y')}{y'(1-y')}\)
\(\frac{\delta Y'}{\delta Z} = \frac{\delta (\sigma(Z))}{\delta Z} = \sigma(Z)[{1 - \sigma(Z)}] = Y'(1 - Y')\)
\(\frac{\delta L}{\delta Y'}\times\frac{\delta Y'}{\delta Z} = \frac{-(Y-Y')}{Y'(1 - Y')}\times Y'(1 - Y') = -(Y-Y')\)
\(\frac{\delta Z}{\delta W^2_{11}} = \frac{\delta (W^2_{11}O_{11} + W^2_{21}O_{12} + b_{21})}{\delta W^2_{11}} = O_{11}\)
\(\frac{\delta L}{\delta W^2_{11}} = \frac{\delta L}{\delta Y'} \times \frac{\delta Y'}{\delta Z} \times \frac{\delta Z}{\delta W^2_{11}} = {-(Y - Y')}O_{11}\)
Let's try to find out the derivative of L with respect to W221 -
\(\frac{\delta L}{\delta W^2_{21}} = \frac{\delta L}{\delta Y'} \times \frac{\delta Y'}{\delta Z} \times \frac{\delta Z}{\delta W^2_{21}}\)
\(\frac{\delta Z}{\delta W^2_{21}} = \frac{\delta (W^2_{11}O_{11} + W^2_{21}O_{12} + b_{21})}{\delta W^2_{21}} = O_{12}\)
\(\frac{\delta L}{\delta W^2_{21}} = \frac{\delta L}{\delta Y'} \times \frac{\delta Y'}{\delta Z} \times \frac{\delta Z}{\delta W^2_{21}} = {-(Y - Y')}O_{12}\)
Let's try to find out the derivative of L with respect to b21 -
\(\frac{\delta L}{\delta b_{21}} = \frac{\delta L}{\delta Y'} \times \frac{\delta Y'}{\delta Z} \times \frac{\delta Z}{\delta b_{21}}\)
\(\frac{\delta Z}{\delta b_{21}} = \frac{\delta (W^2_{11}O_{11} + W^2_{21}O_{12} + b_{21})}{\delta b_{21}} = 1\)
\(\frac{\delta L}{\delta b_{21}} = \frac{\delta L}{\delta Y'} \times \frac{\delta Y'}{\delta Z} \times \frac{\delta Z}{\delta b_{21}} = {-(Y - Y')}\)
Zf = W211O11 + W221O12 + b21
\(\frac{\delta L}{\delta W^1_{11}} = \frac{\delta L}{\delta Y'} \times \frac{\delta Y'}{\delta Z_{f}}\times \frac{\delta Z_{f}}{\delta W^1_{11}}\)
\(\frac{\delta Z_f}{\delta W^1_{11}} = \frac{\delta Z_f}{\delta O_{11}} \times \frac{\delta O_{11}}{\delta Z_{prev}}\times \frac{\delta Z_{prev}}{\delta W^1_{11}}\)
= W211.O11(1 - O11).Xi1
therefore
\(\frac{\delta L}{\delta W^1_{11}} = \frac{\delta L}{\delta Y'} \times \frac{\delta Y'}{\delta Z_{f}}\times \frac{\delta Z_{f}}{\delta W^1_{11}}\) = -(Y - Y') W211O11(1 - O11)Xi1
Similarly
\(\frac{\delta L}{\delta W^1_{21}} = \frac{\delta L}{\delta Y'} \times \frac{\delta Y'}{\delta Z_{f}}\times \frac{\delta Z_{f}}{\delta W^1_{21}}\) = -(Y - Y') W211O11(1 - O11)Xi2
\(\frac{\delta L}{\delta b_{11}} = \frac{\delta L}{\delta Y'} \times \frac{\delta Y'}{\delta Z_{f}}\times \frac{\delta Z_{f}}{\delta b_{11}}\) = -(Y - Y') W211O11(1 - O11)
Zf = W211O11 + W221O12 + b21
\(\frac{\delta L}{\delta W^1_{12}} = \frac{\delta L}{\delta Y'} \times \frac{\delta Y'}{\delta Z_{f}}\times \frac{\delta Z_{f}}{\delta W^1_{12}}\)
\(\frac{\delta Z_f}{\delta W^1_{12}} = \frac{\delta Z_f}{\delta O_{12}} \times \frac{\delta O_{12}}{\delta Z_{prev}}\times \frac{\delta Z_{prev}}{\delta W^1_{12}}\)
= W221.O12(1 - O12).Xi1
therefore
\(\frac{\delta L}{\delta W^1_{11}} = \frac{\delta L}{\delta Y'} \times \frac{\delta Y'}{\delta Z_{f}}\times \frac{\delta Z_{f}}{\delta W^1_{12}}\) = -(Y - Y') W221O12(1 - O12)Xi1
Similarly
\(\frac{\delta L}{\delta W^1_{22}} = \frac{\delta L}{\delta Y'} \times \frac{\delta Y'}{\delta Z_{f}}\times \frac{\delta Z_{f}}{\delta W^1_{22}}\) = -(Y - Y') W221O12(1 - O12)Xi2
\(\frac{\delta L}{\delta b_{12}} = \frac{\delta L}{\delta Y'} \times \frac{\delta Y'}{\delta Z_{f}}\times \frac{\delta Z_{f}}{\delta b_{12}}\) = -(Y - Y') W221O12(1 - O12)
Why BackPropagation?
The loss function is a function of all trainable parameters
L = (Y - Y')
but Y is a constant
Hence, L is a function of Y'
Y' = W211O11 + W221O12 + b21
Y' = W211[W111Xi1 + W121Xi2 + b11] + W221[W112Xi1 + W122Xi2 + b12] + b12
From the above formula, it says that the loss function = Y – Y', where Y is the constant actual value and Y’ is the predicted value. hence Loss function is the only function of Y'. But Y' depends on all 9 trainable parameters.
Hence, we can also say Loss function is a function of all trainable parameters. All 9 parameters will act as a knob for the loss function, through which we can increase or decrease the loss.
Concept Of Gradient
If our mathematical function depend on only one thing such y = f(x) = x2 + x, then we find derivative of y i.e dy/dx = d(fx)/dx = d(x2 + x)/dx = 2x+1
But if our mathematical function depends on two things such as z = f(x,y) = x2 + y2. therefore we will call it a partial derivative(gradient)
Then,\(\frac{\delta z}{\delta x} = 2x\) and \(\frac{\delta z}{\delta y} = 2y\)
Similarly, our loss function depends on 9 trainable parameters, hence we need to find a partial derivative of loss with respect to all trainable parameters. That is why it is called gradient (partial derivative)
Concept Of Derivative-
A derivative is the rate of change both magnitude-wise and sign-wise with respect to a variable.
dy/dx = 4, which means changing the x parameter by 1 unit will also make changes in the y parameter by 4 units.
Concept Of Minima-
Minima can be found by taking the value of the derivative equal to zero.
In image 1st we need to calculate dy/dx and assign it with zero. whatever the value of x our minima will lie on that point.
In image 2nd example for equation Z = X2 + Y2, Z will be minimum, only when the x and y both equal to 0.
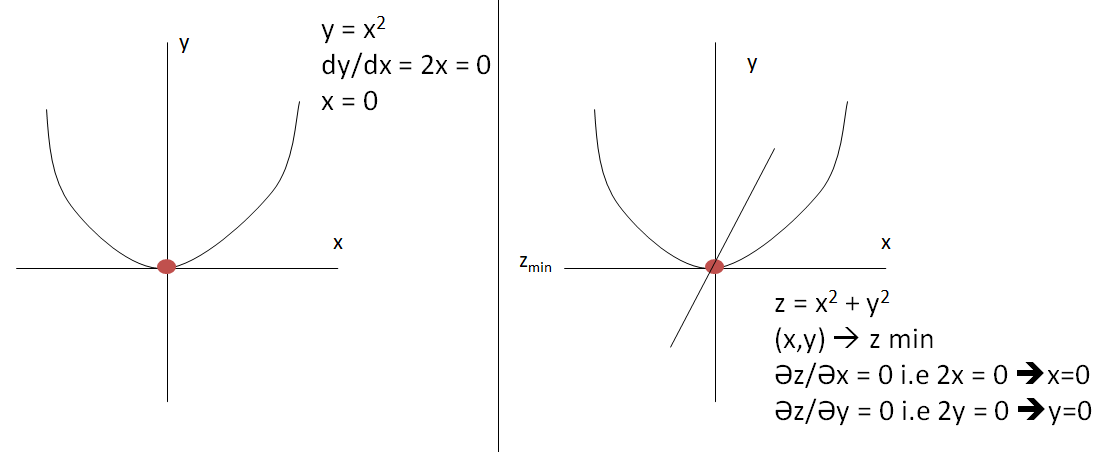
Therefore, we need to find 9 derivatives by assigning them with zero with respect to loss. So that we can get minimum loss.
\(\frac{\delta L}{\delta W^1_{11}},....\frac{\delta L}{\delta b_{12}}=0\)
BackPropagation Intuition-
Wnew = Wold - \(\eta \frac{\delta L}{\delta W} \text{, as }\eta \text{=1}\)
therefore, Wnew = Wold - \( \frac{\delta L}{\delta W} \)
we need to repeat the below step 9 times(i.e 6 Weight and 3 Bias)
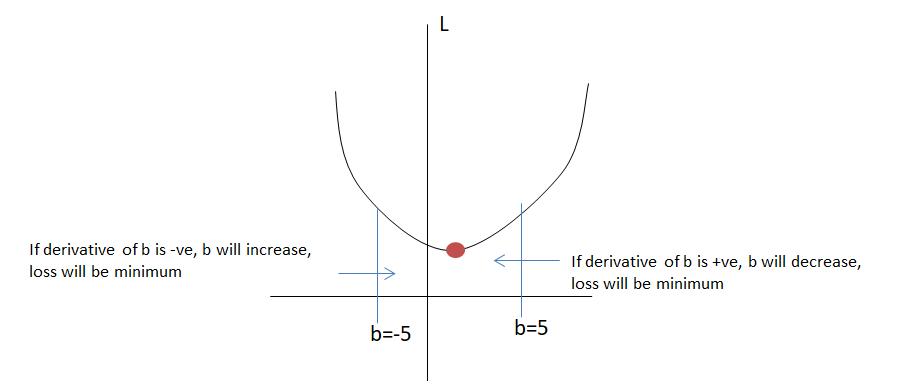
\(b_{21} = b_{21} - \frac{\delta L}{\delta b_{21}}\)
if \(\frac{\delta L}{\delta b_{21}}\) (slope) is +ve then b21 will move in the negative direction and if \(\frac{\delta L}{\delta b_{21}}\) (slope) is -ve then b21 will move in the positive direction. So that loss will be minimal.
Effect Of Learning Rate(\(\eta\))
Without a learning rate, there is a high chance of parameter (W or b) to shoot out i.e. moving from +ve point to extreme negative direction OR moving from -ve point to extreme positive direction. Due to this slope will not reach a minimum and we will never get a minimum loss.
Therefore learning rate is required so that the slope will be reduced/increased slowly and reach to a minimum.
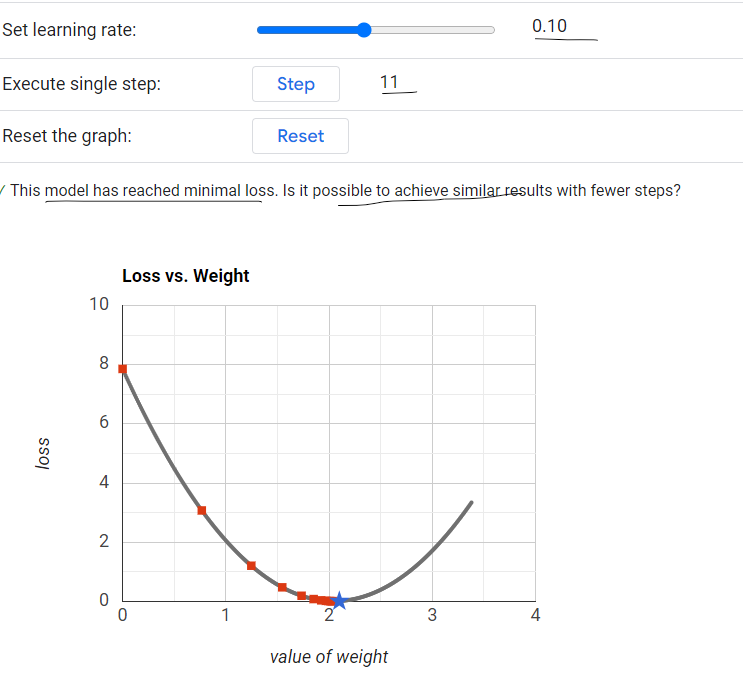
Generally Learning Rate(\(\eta\)) should be 0.1
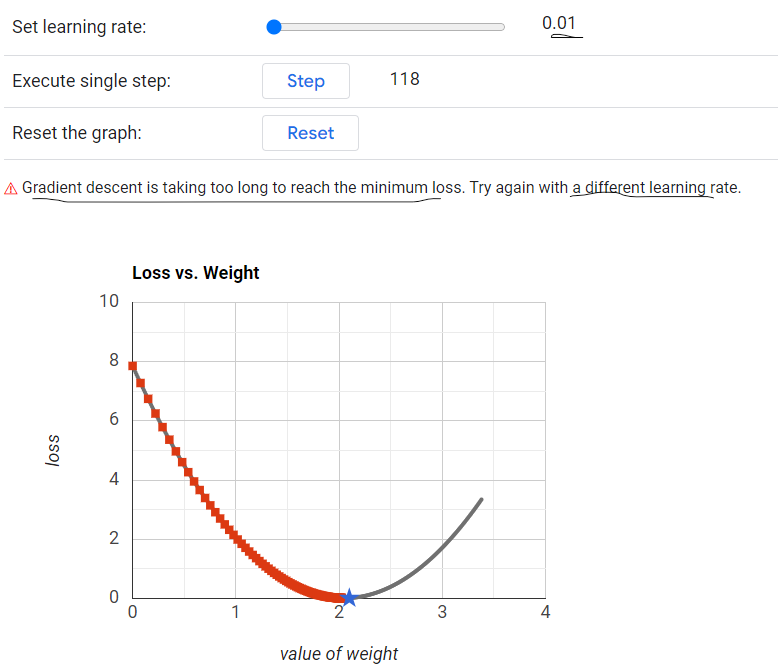
If it is very less like 0.01 then it will not converge to a minima
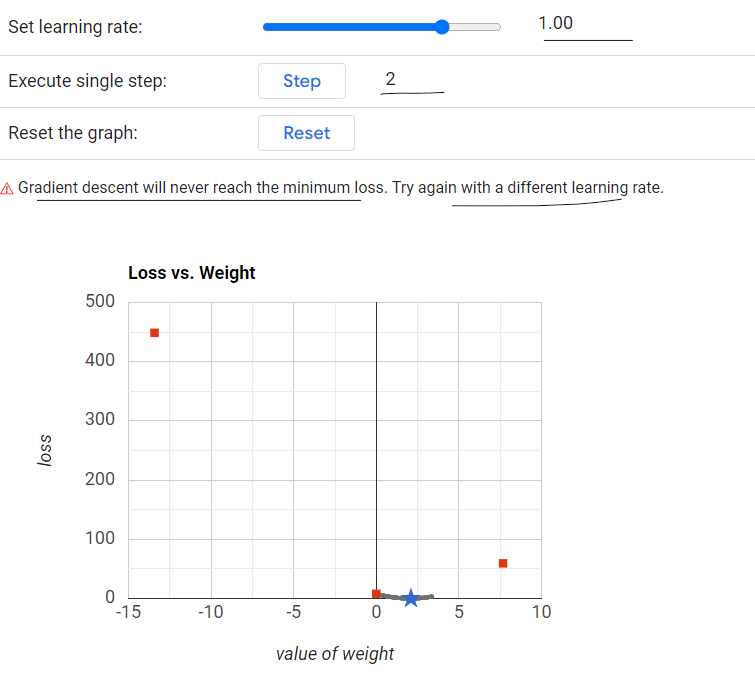
If it is very high like 1 then it will shoot out from a minima.
Learning Rate(\(\eta\)) = 0.01 - It will take too long to reach the minimum loss.
Learning Rate(\(\eta\)) = 0.1 - It will reach the minimum loss in fewer steps.
Learning Rate(\(\eta\)) = 1 - It will never reach the minimum loss.
What is Convergence?
Convergence refers to the stable point found at the end of a sequence of solutions via an iterative optimization algorithm.