Machine Learning - Introduction
Note - This is handmade notes, for best learning please refer-
1] CampusX - https://www.youtube.com/@campusx-official
2] Tutorial Point
3] SimpliLearn
Machine Learning
Machine Learning is a field of computer science that uses statistical techniques to give computer system the ability to “learn” with data, without being explicitly programmed.
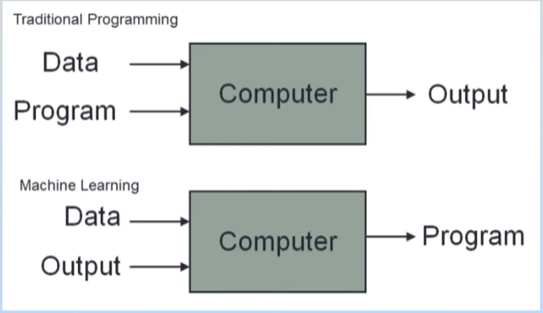
Data Analysis-
Data Analysis is to extract useful information or finding hidden pattern from data by plotting graph and all , and taking the decision based upon the data analysis.
A simple example of Data analysis is whenever we take any decision in our day-to-day life is by thinking about what happened last time or what will happen by choosing that particular decision. This is nothing but analyzing our past or future and making decisions based on it.
Data Mining-
Some hidden pattern cannot be extracted from data analysis. For example finding whether the mail is spam or not. In that case, we will use data mining by applying machine learning model on large dataset to identify patterns or trends in the data that is being mined.
