Deep Learning - CNN - Convolutional Neural Network - Pooling Layer Tutorial
The main purpose of pooling is to reduce/downsample the size of feature maps, which in turn makes translation invariance and computation faster because the number of training parameters is reduced. The pooling operation summarizes the features present in a region, the size of which is determined by the pooling filter.
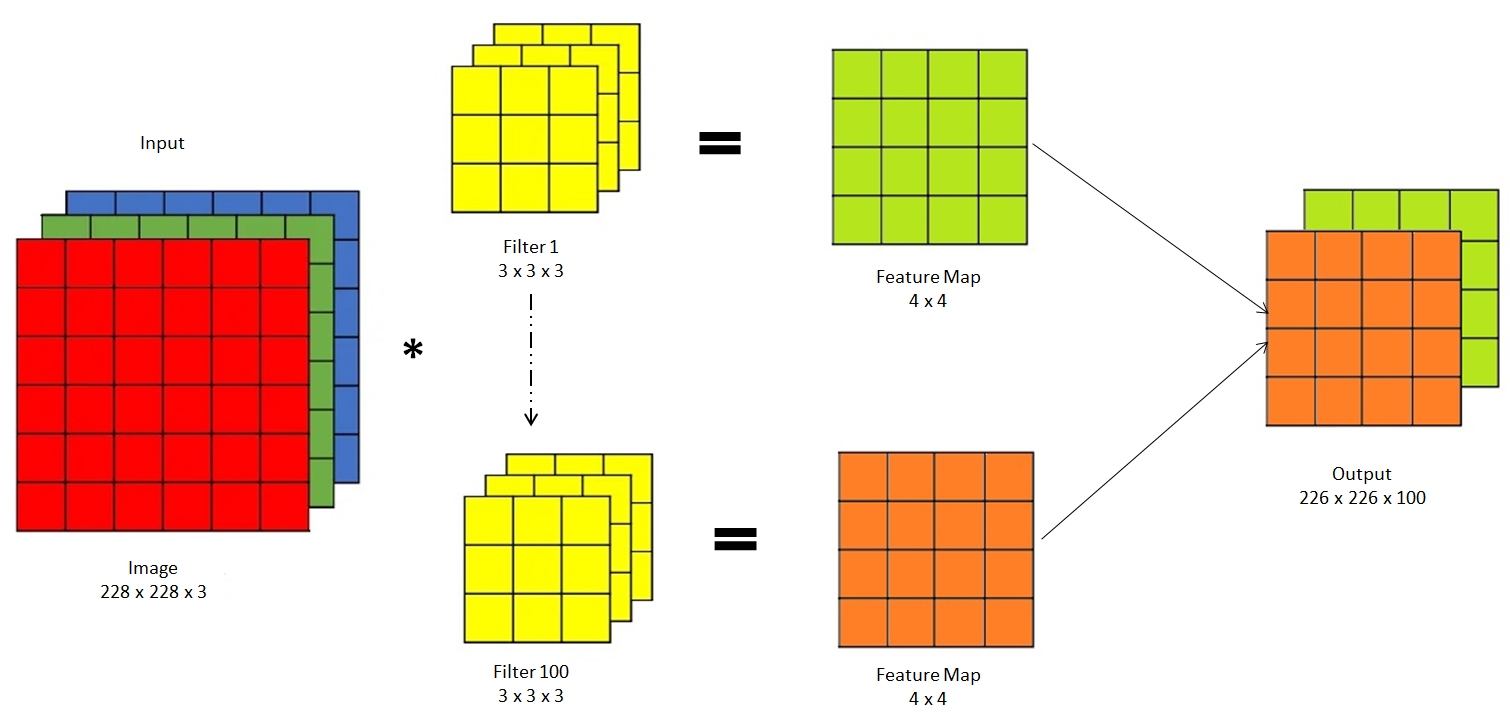
When applying convolution operation on an image you will face two issues i.e.
1] Memory Issue
Suppose you have an RGB image of size 228 x 228 x 3 and pass it through 100 filters of size 3 x 3 x 3, then the resultant feature map is of (226 x 226) x 100 = 5107600
For a 32-bit floating value, it will take around 5107600 x 32 about 19 MB of data. This is just a single training data. For the entire batch, it will take around 1.5 GB of data.
Therefore, we need to reduce the size of the feature map to avoid memory issues.
2] Translation Variation
With Stride also you can reduce memory issues, but more than that we use pooling, the reason is it can solve both the memory issue and translation variance problem
So, what is translation variance?
In convolutional operation, features in an image are location-dependent, which means the feature is tied up with location. therefore in the further layer, it will be treated differently.

In the below image, Cat 1 - Left Ear is at position 5, and Cat 2 - Left Ear is at position 2. Therefore, as per the convolutional operation, both images will be treated differently i.e. Cat 1 and Cat 2 equality is 0%. This is called translation variation but we need Translation Invariance.
Translational Invariance makes the CNN invariant to translation. Invariance to translation means that if we translate the inputs the CNN will still be able to detect the class to which the input belongs. Translational Invariance is achieved using a pooling operation.
Type Of Pooling-
1] Max Pooling
2] Min Pooling
3] Avg Pooling
4] L2 Pooling
5] Global Pooling
1] Max Pooling
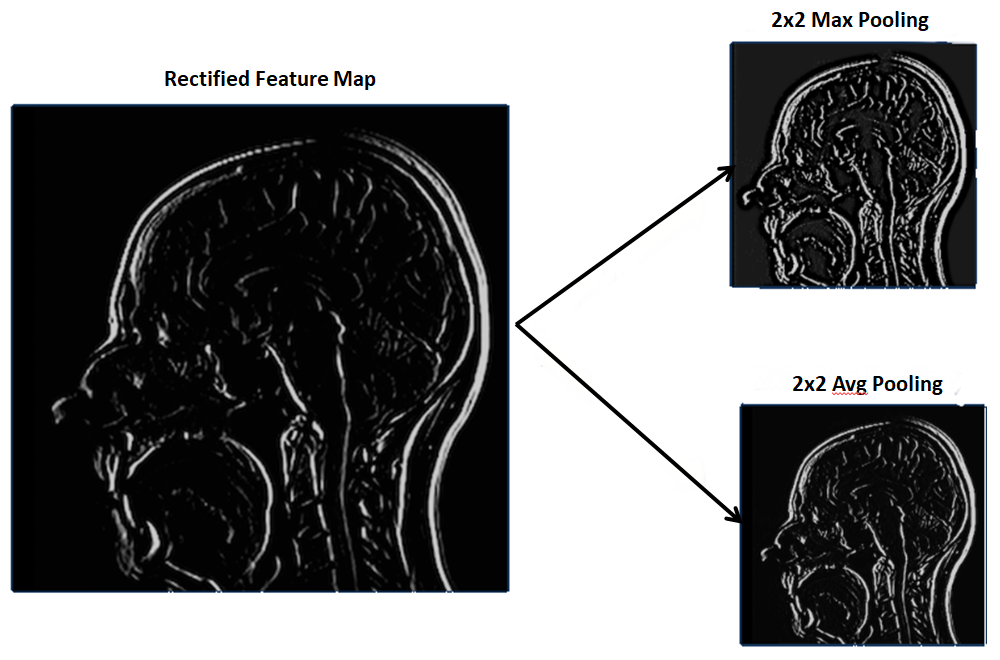
Once you get a non-linear feature map using the input layer and filter, then you can apply max pooling on that feature map.
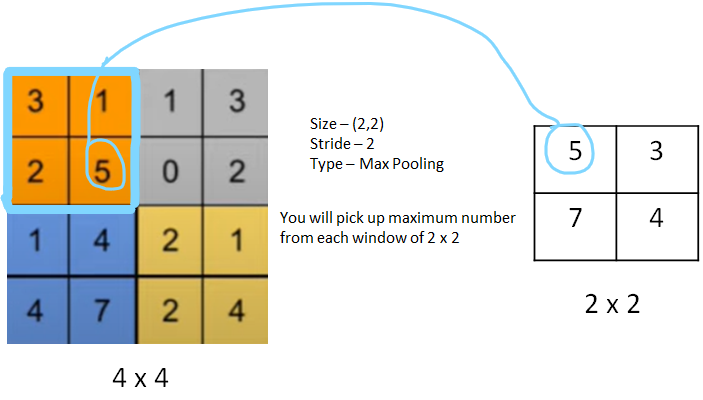
Max pooling is a pooling operation that selects the maximum element from the region of the feature map covered by the filter. Thus, the output after the max-pooling layer would be a feature map containing the most prominent features of the previous feature map(which is a non-linear (using relu) feature map obtained from applying the filter on the input layer)
it will help in keeping the high-level feature and removing the low-level feature.
In min pooling - you will take the minimum element from the region of the feature map covered by the filter.
In average pooling- you will take an average of all elements from the region of the feature map covered by the filter.
In global max pooling, it will take out the max value from the whole feature map.
In global average pooling, it will take out the average value from the whole feature map.
and soon
Pooling on Volume or RGB
In the case of Volume or RGB, we will apply pooling on a 3D shape instead of a 2D shape. Also, the filter will be applied in a 3D shape. Then the Output will be a combination of multiple Feature maps that will also be in 3D
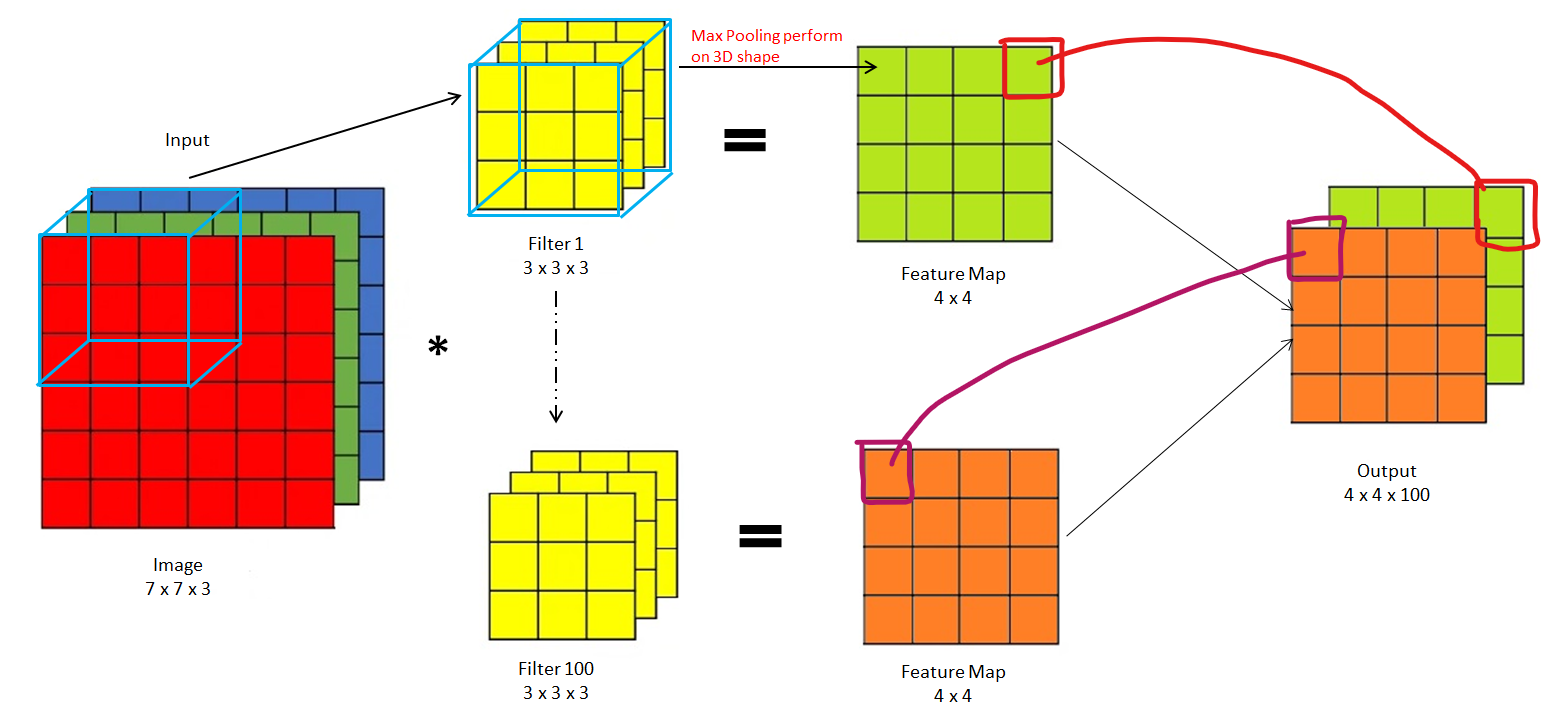
Advantages Of Pooling-
1] Size will be reduced
2] Translation Invariance (will provide more importance to high-level features and ignore the low-level feature)
In the below image, there is a feature is more valuable than feature position
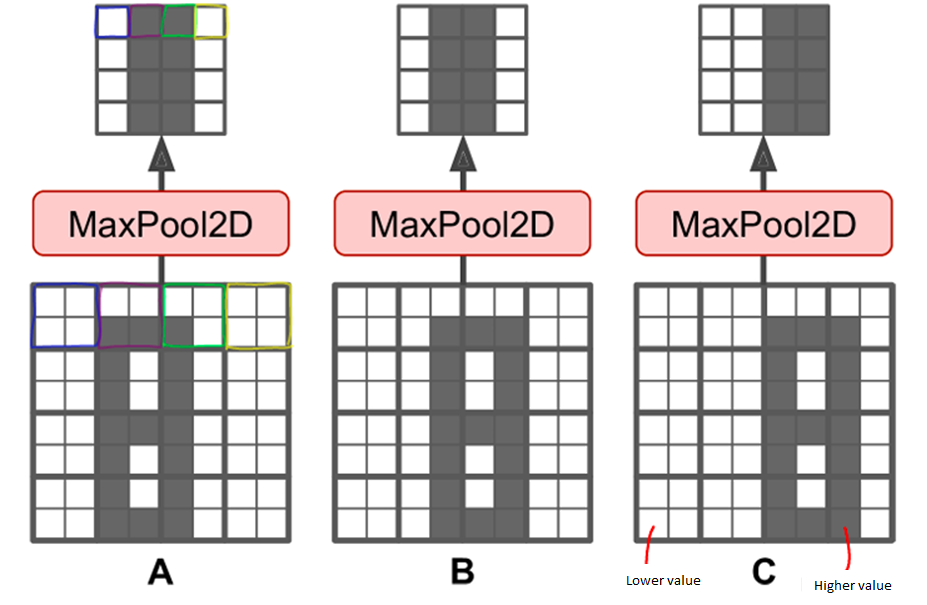
3] Enhanced Feature - only in the case of max pooling, it will try to enhance high-level or dominant features more.
4] No need for training, because we are not doing training, we are just doing an aggregate operation like max-pooling.
In Keras, there is 3 type of pooling i.e
Max Pooling
Average Pooling
Global Pooling - [Global Max and Global Average Pooling]
Disadvantage-
In certain computer vision tasks, where the feature location matter, in that case, we will not use max pooling, because max pooling is feature invariance.