Deep Learning - ANN - Artificial Neural Network - Forward Propagation Tutorial
Forward propagation is the scenario where inputs are passed to the hidden layer with weights. In every single hidden layer, the output of the activation function is calculated until the next layer can be processed. It is called forward propagation as the process begins from the input layer and moves toward the final output layer.
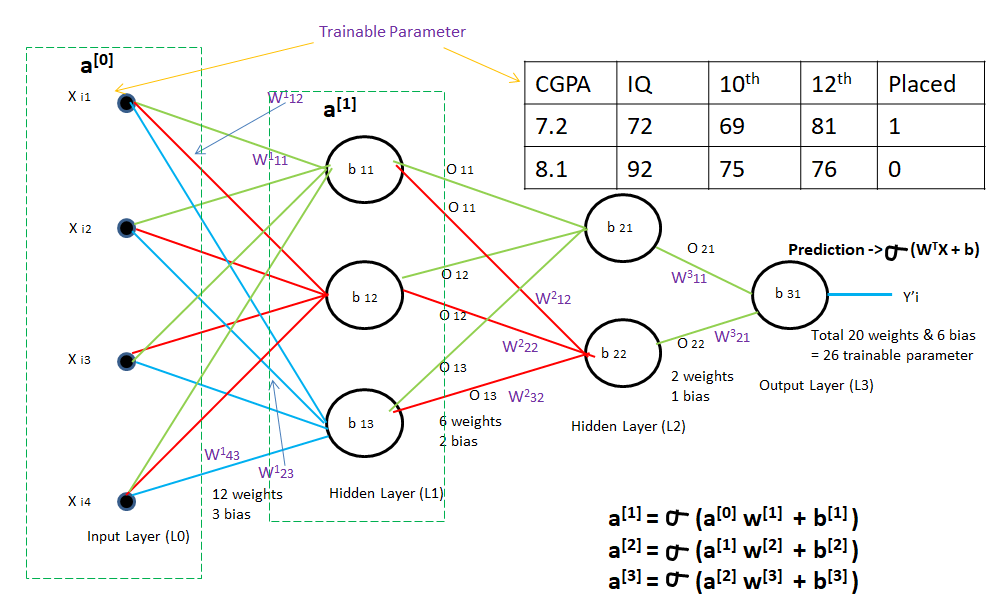
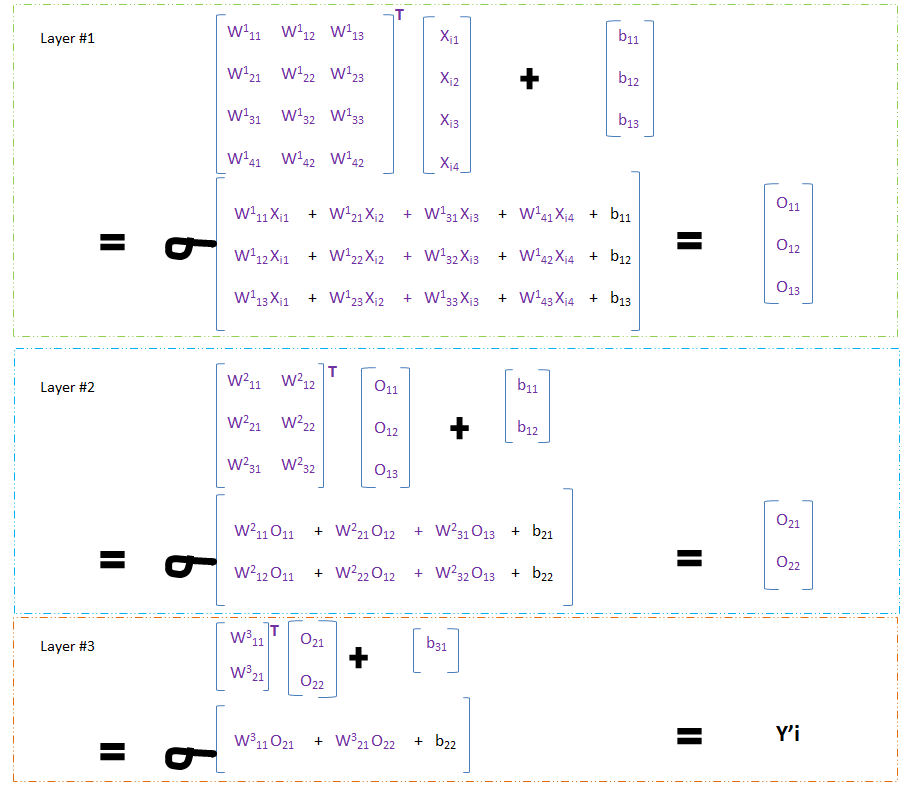
LAYER 1-
Trainable Parameter in L1 = 4 x 3 + 3 = 12 weight + 3 bias = 15
On matrix multiplication of (12 weight and 4 input) and addition of 3 bias based on the formula- m∑i=1(wixi)+bias , the output is O11, O12, and O1.
LAYER 1 Output O11, O12, and O13 will be used as input for LAYER 2.
LAYER 2-
Trainable Parameter in L2 = 3 x 2 + 2 = 6 weight + 2 bias = 8
On matrix multiplication of (6 weight and 3 input) and addition of 2 bias based on the formula- m∑i=1(wixi)+bias , the output is O21 and O22.
Output from LAYER 2 - O21 and O22 will be used as input for LAYER 3.
LAYER 3-
Trainable Parameter in L2 = 2 x 1 + 1 = 2 weight + 1 bias = 3
On matrix multiplication of (6 weight and 3 input) and addition of 2 bias based on the formula- m∑i=1(wixi)+bias , the output is Y'i.
Final Output (Y'i) comes from LAYER 3.
Total Trainable Parameter = 15 + 8 + 3 = 26
Practical 1 - Customer Churn Prediction using ANN | Keras and TensorFlow
Practical 2 - Handwritten Digit Classification using ANN | MNIST Dataset
Practical 3 - Graduate Admission Prediction using ANN
Loss Function-
The loss function is a method of evaluating how well your algorithm is modeling your dataset.
Loss Function in Deep Learning- (Please check in Machine Learning Notes)
1] Regression
- Mean Squared Error
- Mean Absolute Error
- Huber Loss
2] Classification
- Binary Cross Entropy
- Categorical Cross Entropy
- Hinge Loss
3] Autoencoders
- KL Divergence
4] GAN
- Discriminator Loss
- Min Max GAN Loss
5] Object Detection
- Focal Loss
6] Embedding
- Triplet Loss
Loss Function(Error Function) VS Cost Function

MSE- Mean Square error(if no outlier)
MAE – Mean Absolute Error (if outlier)
Huber Loss – if 25% point is outlier
BCE - Binary Cross Entropy (if 2 class)
CCE – Categorical Cross Entropy( if more than 2 class)
SCE – Sparse Cross Entropy( if more than 2 class)