Deep Learning - ANN - Artificial Neural Network - Data Scaling & Feature Scaling Tutorial
Normalization
Normalizing inputs – Bringing the two different inputs (e.g. age and salary) in the same scale.
If we know the min and max value, e.g. CGPA value lies between 0 and 10, then we can use normalize.
For salary, we don’t know the min and max values, and data is not normally distributed, then we can use standardization
Batch Normalization
Batch Normalization is an algorithmic method that makes the training of deep neural networks(DNN) faster and more stable.
It consists of normalizing activation vectors from hidden layers using the mean and variance of the current batch. This normalization step is applied right before (or right after) the nonlinear function.
In Batch Normalization, you will normalize the activation too by making mean zero and standard deviation one.
Why use Batch Normalization?
To normalize the input in the same scale by making mean zero and standard deviation one. So that training will be faster and more stable
Internal Covariate Shift
What is Covariate shift?
A covariate shift is a situation in which the distribution of the model's input features in production changes compared to what the model has seen during training and validation. A covariate shift is a change in the distribution of the model's inputs between training and production data.
Below is a good example of a covariate shift.
Row 1 is trained with only a red rose and Row 2 is the Output saying Not Rose - Shift of Distribution is on the Left Side
Row 3 is trained with all color roses and Row 4 is the Output saying Not Rose - But the shift of Distribution is on the Right Side. This difference in the change of distribution is known as Covariate Shift.

Internal Covariate Shift - is defined as the change in the distribution of network activations due to the change in network parameters during training.

In the above image, consider each child as a hidden layer, input layer will pass “peas” to hidden layer 1, hidden layer 1 will pass “bees” to hidden layer 2, then “knees”, then “cheese” and finally output layer will give output-“fleas”
This shows the change in the information as they pass from the hidden layer because of unnormalized data, due to which distribution will also change and the model will not trained properly.
Batch normalization makes sure that distribution is normally distributed at the end of each layer. which helps in reducing internal covariate shift, So that the model will trained quickly & properly.
How to apply batch normalization?
-
Apply batch normalization using mini-batch gradient descent.
-
Apply batch normalization layer by layer
Z11 → ZN11 → ZBN11 (scale & shift)→ g(ZN11) = A11
Advantages of Batch normalization-
-
make training more stable, because we can set hyperparameter values to a wide range
-
faster because of a higher learning rate
-
help in Regularization
-
Reduce weight initialization impact
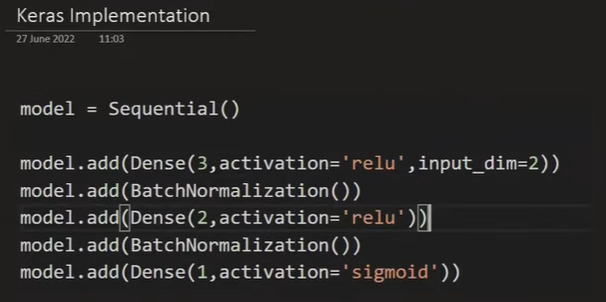

4 because - [gamma weights, beta weights, moving_mean(non-trainable), moving_variance(non-trainable)]
Total parameter in 1st batch normalization is 12 i.e 4 * no. of hidden layer(3) = 12
6 trainable and 6 non-trainable parameter
Total parameter in 2nd batch normalization is 8 i.e 4 * no. of hidden layer(2) = 8
4 trainable and 4 non trainable parameter