Machine Learning - Supervised Learning - LOGISTIC REGRESSION [Regression & Classification] Tutorial
Line Equation in Logistic is – Ax + By + C = 0
Hyperparameter – penalty: l2, l1,elastinet | c is 1/lambda i.e inverse of regularization, smaller value specify stronger regularization. Random_state :
Class_weight:balanced – it will be used when there is imbalanced dataset
Solver : lbfgs for optimization depend on penalty
Max_iter: No. of iteration for the solver to converge
Verbose: to check the result in between of training.
Warm_start: if you stop training in between, warm_start will start training from same point.
n_jobs: To use multiple core, -1 for all core
l1_ratio : when you are using elasticnet
Logistic regression is a statistical analysis method to predict a binary outcome, such as yes or no, based on prior observations of a data set. A logistic regression model predicts a dependent data variable by analyzing the relationship between one or more existing independent variables. It is similar to linear regression. It is supervised machine learning algorithm.

Type of Logistic Regression:
On the basis of the categories, Logistic Regression can be classified into three types:
- Binomial: In binomial Logistic regression, there can be only two possible types of the dependent variables, such as 0 or 1, Pass or Fail, etc.
- Multinomial: In multinomial Logistic regression, there can be 3 or more possible unordered types of the dependent variable, such as "cat", "dogs", or "sheep"
- Ordinal: In ordinal Logistic regression, there can be 3 or more possible ordered types of dependent variables, such as "low", "Medium", or "High".
Perceptron Trick- In perceptron, you start with random line and ask each datapoint, whether it is perfectly classified or not. If not, then the line will move toward that datapoint and make it perfectly classified. If datapoint is already perfectly classified, then line will remain in same position.
It will run till the end of loop (1000) OR while convergence

Positive Region – Ax + By + C >0
Negative Region – Ax + By + C <0
If point is in negative region instead of positive with respect to line, then add the line with datapoint. Else vice versa.
But the transformation can be very large, hence multiply datapoint with learning rate (0.01) and then add or substract.




Problem with Perceptron – In perceptron, once all the point is correctly classified. Then it does not try to improve it. Hence, scikit learn line is far better than perceptron line.
Sigmoid Function (used in binary classification)-
A general mathematical function that has an S-shaped curve, or sigmoid curve, which is bounded, differentiable, and real.
Formula -


Derivative of Sigmoid-The derivative of the sigmoid function σ(x) is the sigmoid function σ(x) multiplied by 1−σ(x).
Logistic Function(used in binary classification)-
A certain sigmoid function that is widely used in binary classification problems using logistic regression. It maps inputs from -infinity to infinity to be from 0 to 1, which intends to model the probability of binary events.
Formula-
Softmax (used in multi-class classification)-
A generalized form of the logistic function to be used in multi-class classification problems. (synonyms: Multinomial Logistic, Maximum Entropy Classifier, or just Multi-class Logistic Regression)
Formula –

Maximum Likelihood-
Maximum likelihood estimation is a probabilistic framework for automatically finding the probability distribution and parameters that best describe the observed data.

Log Loss (Binary Cross-Entropy Loss) (used in Binary classification)-
A loss function that represents how much the predicted probabilities deviate from the true ones. It is used in binary cases.
Formula-
It is used for binary classification problem, if we have only two class like ‘YES’ or ‘NO’
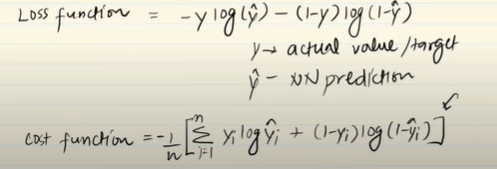
Advantage –Graph is differentiable at all point
Disadvantage –Multiple Local minima
Cross-Entropy Loss OR Categorical Cross Entropy(used in multi-class classification)-
A generalized form of the log loss, which is used for multi-class classification problems.
It is used for multiclass classification problem. If we have more than 2 class for example – Morning, Evening , Night.
Activation Function to be used is Softmax to train Multilayer Perceptron and no. of output should be same as no. of class.

Difference between Sparse Categorical Cross Entropy and Categorical Cross Entropy is?

Both are same, only difference is Sparse Categorical Cross Entropy is fast, because in this there is no need to do one hot encoding
Formula for cost function

Negative Log-Likelihood(used in multi-class classification)-
Another interpretation of the cross-entropy loss using the concepts of maximum likelihood estimation. It is equivalent to cross-entropy loss.
Formula-
