Machine Learning - Supervised Learning - Entropy Tutorial
It is randomness or measurement of disorder. In other word you can also call it as the measure of impurity.
If entropy(disorder) is higher, then it will be difficult to draw any conclusion from that piece of information.
Consider a data set having a total number of N classes, then the entropy (E) can be determined with the formula below

Where;
Pi = Probability of randomly selecting an example in class I;

Let's understand it with an example where we have a dataset having three colors of fruits as red, green, and yellow. Suppose we have 2 red, 2 green, and 4 yellow observations throughout the dataset, total is 8. Then as per the above equation:
E = −( Pr log2 Pr + Pg log2 Pg + Py log2 Py)
Where;
Pr = Probability of choosing red fruits = 2/8 = 1/4 ;
Pg = Probability of choosing green fruits = 2/8 = 1/4;
Py = Probability of choosing yellow fruits = 4/8 = 1/2;
Now our final equation will be such as;
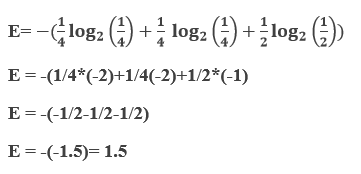
So, entropy will be 1.5.
Let's consider a case when all observations belong to the same class; then entropy will always be 0.
E = −(1log21)
= 0

When entropy becomes 0, then the dataset has no impurity. Datasets with 0 impurities are not useful for learning. Further, if the entropy is 1 i.e probability is 0.5, then this kind of dataset is good for learning.


Use of entropy in decision tree
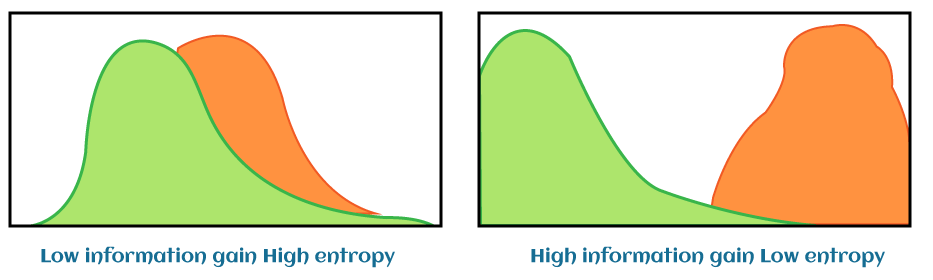
In decision trees, heterogeneity in the leaf node can be reduced by using the cost function. At the root level, the entropy of the target column can be determined by the Shannon formula, in which weighted entropy is the individual weight of each attribute. Further, weights are considered as the probability of each class individually. The more the decrease in entropy, the more information is gained.