Machine Learning - Ensemble Learning - Basic Ensemble Techniques Tutorial
- Voting Classifier - Max Voting (for classification)
The max voting method is generally used for classification problems. In this technique, multiple models are used to make predictions for each data point. The predictions by each model are considered as a ‘vote’. The predictions which we get from the majority of the models are used as the final prediction.
In the simple, same dataset, different algorithms (base model) are used in this technique.
Example-
The result of max voting would be something like this:
|
Classifier 1 |
Classifier 2 |
Classifier 3 |
Classifier 4 |
Classifier 5 |
Final |
|
4 |
4 |
4 |
5 |
5 |
4 |
Two types of the voting classifier are-
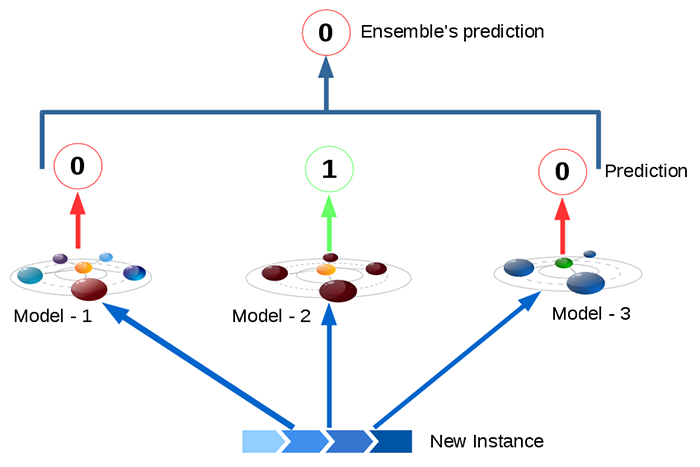
Hard Voting-
The classification output of all the individual models is calculated and the mode value of the combined output is given as the final output value.
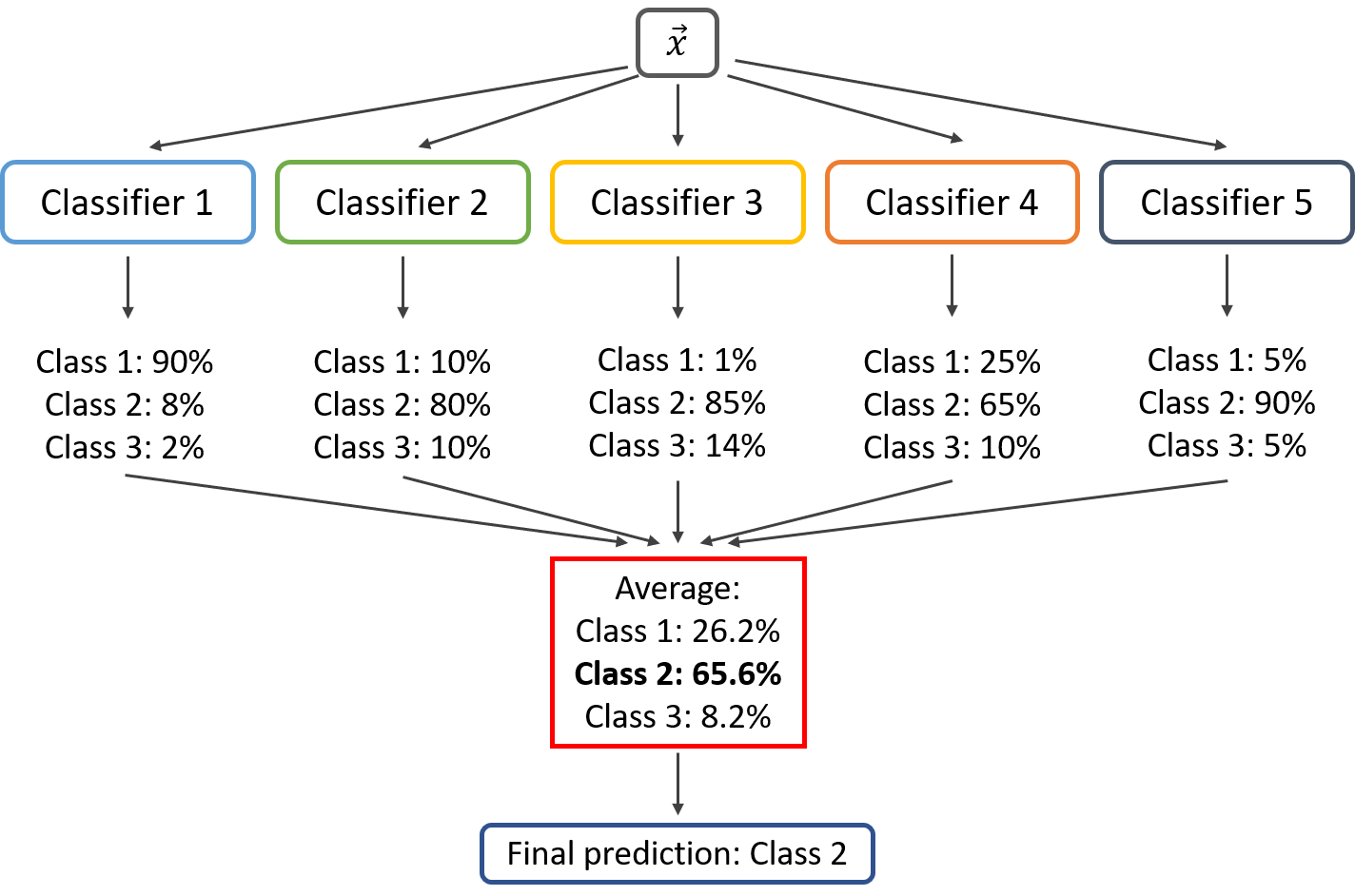
Soft Voting
In soft voting, every individual classifier provides a probability value of specific class. In this, weighted average from all the classifier is calculated for each class. Then the final prediction will be class with highest weight.
Other Example, which will explain both hard voting and soft voting can give different results-
|
M1 |
M2 |
M3 |
Result |
|||||
|
1 |
0 |
1 |
0 |
1 |
0 |
|||
|
Using Probability Soft Voting |
10% |
90% |
55% |
45% |
55% |
45% |
1 probabilty is 40% 0 probability is 60%. Hence the actual result is 0 |
|
|
Using Mode Hard Voting |
0 |
1 |
1 |
On the basis of mode actual result is 1 |
||||
Hence both voting classifications give different predictions. But Soft voting is using weight for each model. Hence, soft voting is best than hard voting.
Voting Classifier – Averaging (for regression)
Similar to the max voting technique, multiple predictions are made for each data point in averaging. In this method, we take an average of predictions from all the models and use it to make the final prediction. Averaging can be used for making predictions in regression problems or while calculating probabilities for classification problems.
In the simple, same dataset, different algorithms (base model) are used in this technique.
For example, in the below case, the averaging method would take the average of all the values.
i.e. (5+4+5+4+4)/5 = 4.4
|
Colleague 1 |
Colleague 2 |
Colleague 3 |
Colleague 4 |
Colleague 5 |
Final |
|
5 |
4 |
5 |
4 |
4 |
4.4 |
Weighted Average
This is an extension of the averaging method. All models are assigned different weights defining the importance of each model for prediction. For instance, if two of your colleagues are critics, while others have no prior experience in this field, then the answers by these two friends are given more importance as compared to the other people. E.g Stacking
The result is calculated as [(5*0.23) + (4*0.23) + (5*0.18) + (4*0.18) + (4*0.18)] = 4.41
|
Colleague 1 |
Colleague 2 |
Colleague 3 |
Colleague 4 |
Colleague 5 |
Final |
|
|
rating |
5 |
4 |
5 |
4 |
4 |
|
|
weight |
0.23 |
0.23 |
0.18 |
0.18 |
0.18 |
4.41 |