Statistics for AIML - Regression Metrics - Skewness Tutorial
It is the degree of distortion from the symmetrical bell curve or the normal distribution. It measures the lack of symmetry in data distribution. A symmetrical distribution or normal distribution will have a skewness of 0.
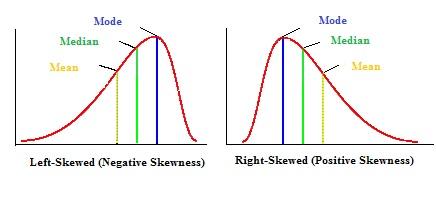
Right Skew(Positive Skew)- Mean>Median>Mode
Left Skew(Negative Skew) – Mode>Median>Mean
No Skew – Mean = Median = Mode
You can check skewness using boxplot, distplot, depend on count.
Python code
import numpy as np
from scipy.stats import skew
x = np.random.normal(0,2,10000) # create random values based on a normal distribution
print(skew(x))
Checking Skewness Through BoxPlot

So, when is the skewness too much?
The rule of thumb seems to be:
- If the skewness is between -0.5 and 0.5, the data are fairly symmetrical.
- If the skewness is between -1 and -0.5(negatively skewed) or between 0.5 and 1(positively skewed), the data are moderately skewed.
- If the skewness is less than -1(negatively skewed) or greater than 1(positively skewed), the data are highly skewed.
Example
Let us take a very common example of house prices. Suppose we have house values ranging from $100k to $1,000k with the average being $500k. If the peak of the distribution was left of the average value, portraying a positive skewness in the distribution. It would mean that many houses were being sold for less than the average value, i.e. $500k. This could be for many reasons, but we are not going to interpret those reasons here. If the peak of the distributed data was right of the average value, that would mean a negative skew. This would mean that the houses were being sold for more than the average value.