Statistics for AIML - Descriptive statistics - Overview Tutorial
It deals with the processing of data without attempting to draw any inferences from it. The characteristics of the data are described in simple terms. Events that are dealt with include everyday happenings such as accidents, prices of goods, business, incomes, epidemics, sports data, and population data.
For example - the government conducted a survey to find the number of families below the poverty line. where some volunteers will be part of and collect data by visiting each family so the government can get actual data. This is descriptive Statistics because no inferences are drawn from it.
If the population is very large and it is difficult to count or get the data. Then we will go with Inferential Statistics.
It summarizes the basic features of a dataset found in a given study, for example- mean, median, mode, standard deviation, variance, etc.
Measures of Central Tendency – Mean, Median, and Mode
Measures of Dispersion – Standard Deviation, Variance, Range, IQR (Inter Quartile Range)
Measures of Symmetricity/Shape – Skewness and Kurtosis
Measures of Central Tendency -
A measure of central tendency is a summary statistic that represents the center point or typical value of the dataset. These measures indicate where the most values in a distribution fall and are also referred to as central location distribution.
1] Mean
The average value of the st of Numbers. Mean is a number around which a whole data is spread out. Denoted by u for the population means and for the sample mean.
Example: Find the mean of 5,5,2,6,3,8,9?
A: Mean is (5+5+2+6+3+8+9)/7 = 38/7 = 5.43
2] Median
The median is the value that divides the data into 2 equal parts i.e. number of terms on the right side of it is the same as the number of terms on the left side of it when data is arranged in either ascending or descending order.
(Note: If you sort data in descending order, it won't affect the median but IQR will be negative. IQR will be discussed in the next slide.)
Example: Find the median of 5,5,2,6,3,8,9.
A: Putting it in ascending order = 2,3,5,5,6,8,9. Hence, Median = Mid Number = 5.
(Note: The Median of an even set of numbers can be found by taking the average of the 2 middle numbers.
E.g. Median of 2,3,4,7 = average of (3 and 4) = 3.5 )
3] Mode
Mode is the term appearing the maximum time in the data set i.e. term that has the highest frequency.
Example: find the Median of 5,5,2,6,3,8,9.
A: Mode = Maximum number of repetitions in dataset = 5. Hence, Mode = 5.
(Note: If there is no repetition of data then mode is not present. E.g.: What is the mode of 1,2,3,5,6?
A: None i.e. mode is not present.)
Library - numpy for mean and median, scipy-stats for mode
Visualization - Frequency Distribution Table, Cumulative Frequency, Cross Table
Normal Distribution (Gaussian Distribution)
Property - Symmetrical, Center (peak point) is Mean, Mean = Median = Mode, Area under curve is 1, empirical law of 68 – 95 – 99 rule.
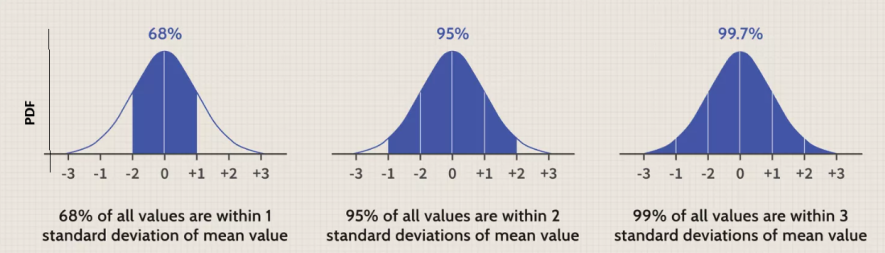
EMPIRICAL RULE
The empirical rule states that for a normal distribution, nearly all of the data will fall within three standard deviations of the mean. The empirical rule can be broken down into three parts:
- 68% of data falls within the first standard deviation from the mean.
- 95% fall within two standard deviations.
- 99.7% fall within three standard deviations.

The rule is also called the 68-95-99.7 Rule or the Three Sigma Rule.
PDF OF A NORMAL DISTRIBUTION AND ORIGIN OF EMPIRICAL FORMULA

Empirical Formula of Normal Distribution: The empirical rule, also referred to as the three-sigma rule or 68-95-99.7 rule, is a statistical rule that states that for a normal distribution, almost all data falls within three standard deviations (denoted by σ) of the mean (denoted by µ). Broken down, the empirical rule shows that almost 68% fall within the first standard deviation (µ ± σ), almost 95% within the first two standard deviations (µ ± 2σ), and almost 99.7% within the first three standard deviations (µ ± 3σ).
Probability Distribution/Density Function – It will provide a probability for a value in a certain range. Visualize it using DistPlot, FacetGrid
KDE – Kernel Density Estimation draws a Gaussian bell curve with probability on the y-axis. If KDE= False, it will act like a histogram
Cumulative Distribution Function – It is a probability distribution that contains the probabilities that a random variable X is less than or equal to X.


Measures Of Spread / Measures of Dispersion -
It gives an idea about how much data is spread. Some important measure is Range, IQR, Variance, and Standard Deviation
Range - The Range is described by subtracting lower value from higher value. The wide range indicates high variability, and the small range specifies low variability in the distribution.
Range = Highest_value – Lowest_value
Percentile – A percentile is a measure used in statistics indicating the value below which a given percentage of observations in a group of observations falls.
For example – the 20th percentile is the value below which 20% of the observations may be found.
Quartile –Quartiles are the values that divide a list of numbers into quarters.
Interquartile Range (IQR)- IQR is a range between the third and first quartile. IQR is preferred over a range because IQR is not influenced by outliers like a range. IQR is used to measure variability by splitting a data set into four equal quartiles.


Formula To Find Outliers
[Q1 – 1.5 * IQR, Q3 + 1.5 * IQR]
If the value does not fall in the above range it considers outliers.

Mean Absolute Deviation -
The mean absolute deviation of a dataset is the average distance between each data point and the mean. It gives us an idea about the variability in a dataset.
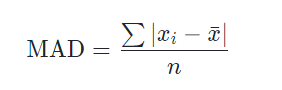
Xi = Each value from the population
Xbar = The population mean
n = Size Of Population
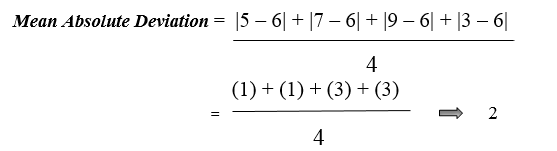
Here | gives the absolute value that means all negative deviation (distance) made positive.
Why MAD (Mean Absolute Deviation) is not used instead of variance?
- MAD is not differentiable at 0. It will not work in optimization. While variance is differentiable
- The squared is used in variation during calculation because they weigh outliers more heavily than points that are near to mean. This prevents differences above the mean and neutralizes those below the mean.
Median Absolute Deviation is similar to Mean Absolute Deviation, where instead of mean, median value is used.
Variance -
The variance is a measure of variability. It is calculated by taking the average of squared deviations from the mean. Variance tells you the degree of spread in your data set. The more spread the data, the larger the variance is in relation to the mean.
Population vs. Sample Variance
Population variance
When you have collected data from every member of the population
The population variance formula looks like this:
|
Formula |
Explanation |
|---|---|
|
|
|
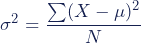
 = population variance
= population variance = population mean
= population meanSample variance
When you have collected data from a sample
The sample variance formula looks like this:
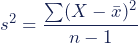
= sample variance
= summation from 1 to n-1
- Χ = each value
= sample mean
- n = number of values in the sample
Why do we use n-1 in the sample deviation and variance formula instead of n?
The simple answer: the calculations for both the sample standard deviation and the sample variance both contain a little bias (that’s the statistics way of saying “error”) estimate that consistently underestimates variability. Bessel’s correction (i.e. subtracting 1 from your sample size) corrects this bias. In other words, sample variance would tend to be lower than the real variance of the population. Therefore to get an accurate result same as the population, we use n-1 instead of n.
The standard deviation is derived from variance and tells you, on average, how far each value lies from the mean. It’s the square root of variance.
A low standard deviation indicates that the data points tend to be close to the mean of the data set, while a high standard deviation indicates that the data points are spread out over a wider range of values.
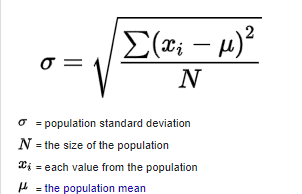
In Python:
Population STD = pstdev()
Sample STD = stdev()

Variance Vs Standard Deviation
Both measures reflect variability in distribution, but their units differ:
- Standard deviation is expressed in the same units as the original values (e.g., meters).
- Variance is expressed in much larger units (e.g., meters squared)
Why Standard Deviation is mostly used instead of variance?
- The problem with variance is that because of squaring. It is not the same unit of measure as the original data.
Variance Proportional to Spread
Variance gives added weight to the values that impact outliers (the numbers that are far from the mean and squaring of these numbers can skew the data like 10 square is 100, and 100 square is 10,000 ) to overcome the drawback of variance, standard deviation came into the picture.
Measures of Symmetricity/Shape
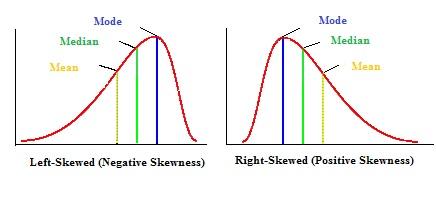
Skewness
It is the degree of distortion from the symmetrical bell curve or the normal distribution. It measures the lack of symmetry in data distribution. A symmetrical distribution will have a skewness of 0.
Right Skew(Positive Skew)- Mean>Median>Mode
Left Skew(Negative Skew) – Mode>Median>Mean
No Skew – Mean = Median = Mode
You can check skewness using boxplot, distplot, depending on count.
Kurtosis
Kurtosis is a statistical measure that defines how heavily the tails of a distribution differ from the tails of a normal distribution. In other words, kurtosis identifies whether the tails of a given distribution contain extreme values
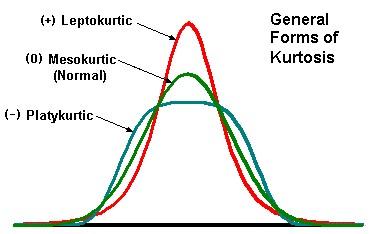
High kurtosis in a data set is an indicator that data has heavy tails or outliers. If there is a high kurtosis, then, we need to investigate why do we have so many outliers. It indicates a lot of things, maybe wrong data entry or other things. Investigate!
Low kurtosis in a data set is an indicator that data has light tails or lack of outliers. If we get low kurtosis(too good to be true), then also we need to investigate and trim the dataset of unwanted results.