Statistics for AIML - Inferential Statistics - Bias Variance Trade Off Tutorial
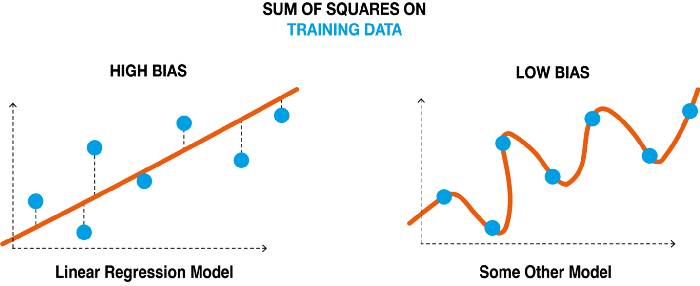
Bias – The inability of machine learning model to truly capture the relationship between training data and learning line. If the difference between the predicted value and actual value in training data is more then it is highly biased, else it is less biased.
Variance - The spread of our data is called the variance of the model. The model with high variance has a best fit on training data(overfit) and thus is not able to fit accurately on the test data. As a result, such models perform very well on training data but has high error rates on test data.
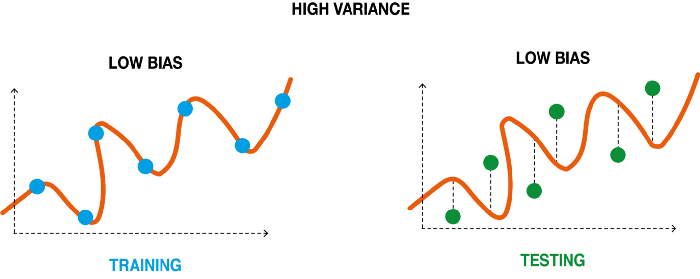
Overfit - Overfitting occurs when our machine learning model tries to capture all the data points or more than the required data points of the training dataset. The overfitted model has low bias and high variance.
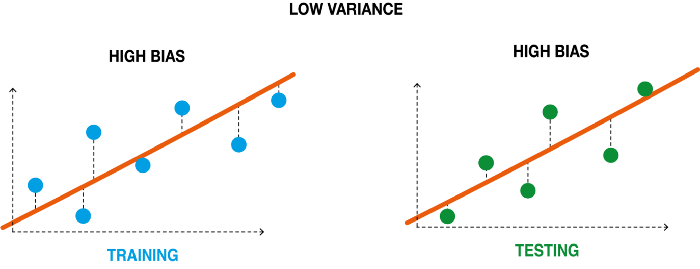
Underfit - Underfitting occurs when our machine learning model is not able to capture the underlying trend of the data. The under fitted model has high bias and low variance.

Bias-Variance trade-off
The bias-Variance trade-off is about finding the sweet spot to make a balance between bias and variance errors.
While building the machine learning model, it is really important to take care of bias and variance in order to avoid overfitting and underfitting in the model. If the model is very simple with fewer parameters, it may have low variance and high bias. Whereas, if the model has a large number of parameters, it will have high variance and low bias. So, it is required to make a balance between bias and variance errors(low bias and low variance), and this balance between the bias error and variance error is known as the Bias-Variance trade-off.
https://www.javatpoint.com/bias-and-variance-in-machine-learning
Total Error
To build a good model, we need to find a good balance between bias and variance such that it minimizes the total error.

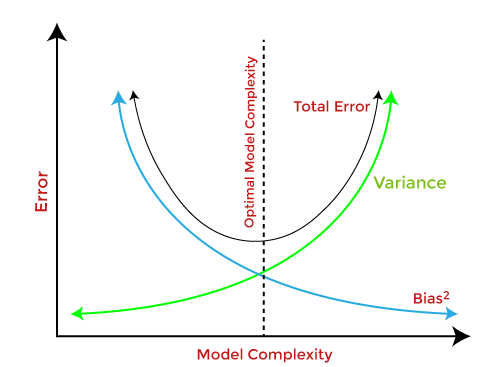
To find the Bias variance trade-off or to reduce overfitting, three methods are used i.e. regularization, bagging, and boosting.