Statistics for AIML - Inferential Statistics - Hypothesis Testing Tutorial
Hypothesis testing is a statistical method which is used to make decision about entire population, with the help of only sample data. To make this decision, we come up with a value called as p-value.
The process of gathering data and evaluating the claims or hypotheses with the goal to reject or otherwise (failing to reject) is termed as hypothesis testing
Hypothesis testing helps the businesses and researchers, to make better decisions based on the acceptance and rejection of assumption.
Hypothesis in simple it is assumption
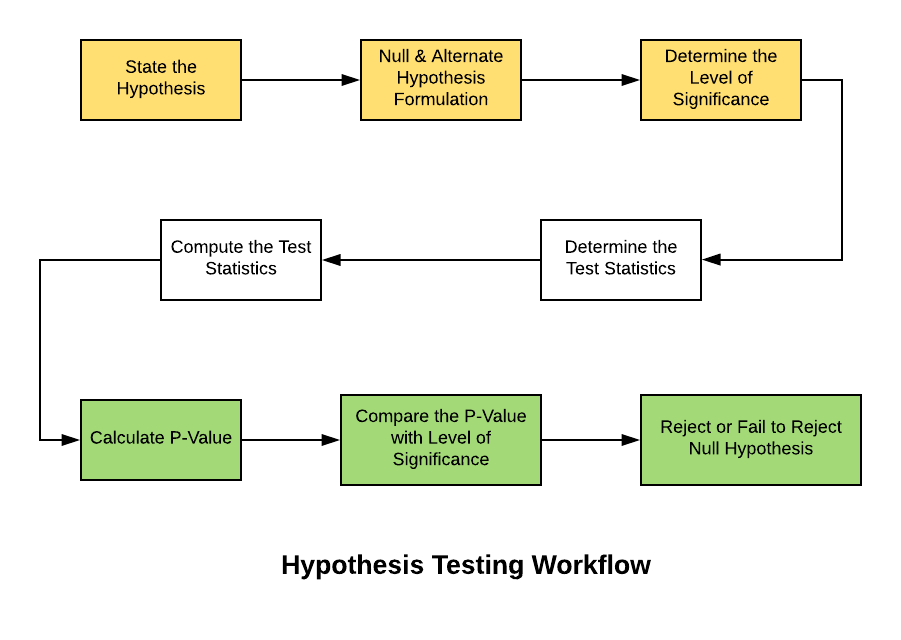
Step 1- State the Hypothesis
the following hypothesis can be stated for doing hypothesis testing-
-
The packet of 500 gm of sugar contains sugar of weight less than 500 gm. (Claim made against the established fact)
-
The housing price depends upon the average income of the people staying in the locality. (Claim to establish new truth)
-
Running 5 miles a day results in a reduction of 10 kg of weight within a month. (Claim to establish new truth)
The hypothesis could either be the statement that is assumed to be true or the claim which is made to be true.
Step 2- Null & Alternate Hypothesis Formulation
Types Of Hypothesis-
-
Null hypothesis: Null hypothesis is a type of hypothesis in which we believe that our assumption is true before testing hypothesis. That is the reason we never say accept the null hypothesis, because it is already believed to be true. Instead we say failed to reject null hypothesis.
It is denoted by H0.
H0 must always contain equality(=).
Example- Our Null Hypothesis assumption is that vanilla icecream taste similar like choclate icecream.
i.e Ho : Vanilla Icecream = Chocolate Iceream
-
Alternate hypothesis: Alternate hypothesis is an something opposite to null hypothesis.
In this we would like to prove null hypothesis false. Therefore we say reject null hypothesis.
An alternate hypothesis is denoted by H1 or Ha.
Ha always contains difference(≠, >, <).
Example- Our Alternate Hypothesis assumption is that vanilla icecream taste different than the choclate icecream.
i.e Ha : Vanilla Icecream ≠ Chocolate Icecream
OR
Vanilla Icecream > Chocolate Icecream
OR
Vanilla Icecream < Chocolate Icecream
Step 3 – Determine the level of significance
Significance Level - The significance level is a probability of rejecting the null hypothesis when it is actually true. It is denoted by alpha ( α ). It is determined before conducting the experiment.
In many statistical analyses, we observe something written as — “ with a 95% confidence interval”. This statement, actually tells us about the significance level, such that,
Confidence Interval = 1 — Significance Level
so, here “95% confidence interval” tells us that Significance Level is 0.05. This means there is a 5% probability that there is a difference in the groups being compared when in reality there is no difference i.e. 5% is the probability of rejecting the null hypothesis.
In our icecream example, there is 5% probability that vanilla icecream taste different than the choclate icecream. But in reality, vanilla icecream taste similar like choclate icecream.
Hence, the significance level is used to determine, whether the Null Hypothesis should be rejected or retained. To reject the null hypothesis, the observed effect of the data has to be significant (i.e observed effect of the data should be in rejection region).
Usually, the significance level of 1% is considered for the medical field and 5% for research and business.
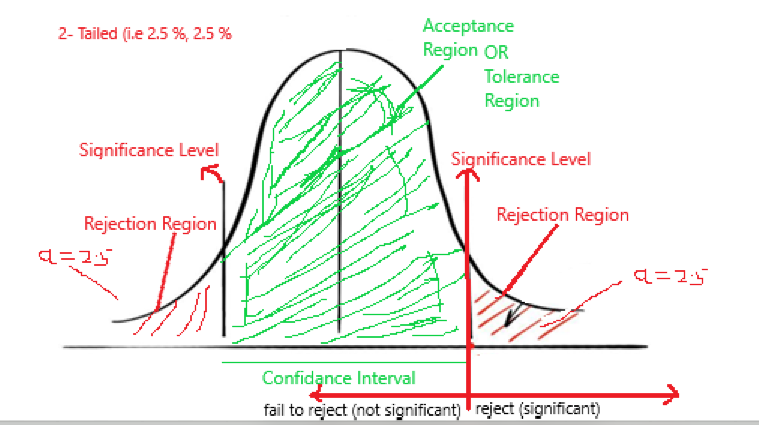
One Tailed & Two Tailed –
Two Tailed-
If Rejection Region are in both the end of Acceptance region. Then it is two tailed. If level of significance is 5%. Then rejection region is equally distributed at both the end. i.e 2.5% and 2.5%.
For example-
Example- Our Null Hypothesis assumption is that vanilla icecream taste similar like choclate icecream.
i.e Ho : Vanilla Icecream = Chocolate Icecream
Then it is possibility that Vanilla Icecream ≠ Chocolate Icecream, which means
1] Vanilla Icecream > Chocolate Icecream
2] Vanilla Icecream < Chocolate Icecream
Hence, 2 possibility in alternate hypothesis, therefore it is called as two tailed.
One Tailed-
If Rejection Region are in only one of the end of Acceptance region. Then it is one tailed. If level of significance is 5%. Then rejection region is 5 %, which can be either one of the end.
For example-
Example- Our Null Hypothesis assumption is that vanilla icecream taste good than the choclate icecream.
i.e Ho : Vanilla Icecream > Chocolate Icecream
Then it is possibility that
1] Vanilla Icecream =< Chocolate Icecream
Hence, 1 possibility in alternate hypothesis, therefore it is called as one tailed.
Step 4 – Determine & Compute the test statistics
A test statistic is a statistic used in hypothesis testing. This helps in deciding to support or reject the null hypothesis. Next step is to calculate the test statistics (z-test, t-test, f-test, etc) to determine the P-value. If the sample size is more than 30, it is recommended to use z-statistics. Otherwise, t-statistics could be used.
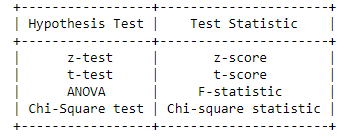
Here we are going to cover only the z-test and t-test.
z-test:
z-test is a type of inferential statistics used to determine the statistical difference between a sample and a population mean when the population's variance is known. The z-test should be used when,
-
The sample size is greater than 30. Because according to Central Limit Theorem, when the number of samples increases, their mean distribution becomes similar to normal distribution.
-
The data is normally distributed.
-
Data points are independent of each other.
-
Samples are independent of each other.
-
There is an equally likely chance for each data points to be picked up to a sample.
To calculate z-score for a population, we need sample mean(µ), sample s.d. (σ), the population mean(x), and the number of samples(generally >30) as shown below.

Note: The z-score tells you how far, in standard deviations, a data point is away from the mean of a data set.
t-test:
Like z-test, a t-test is a type of inferential statistics used to determine the statistical difference between a sample and a population mean, but most useful when determining the statistical difference between two independent sample groups where the population variance is unknown. The t-test should be used when,
-
The variance of the population is unknown.
-
The sample size is less than 30.
-
The mean of the sample distributions follows a normal distribution.
-
The variance of each sample is homogeneous, or the standard deviations of samples are approximately equal.
-
The formula to calculate t-value is,
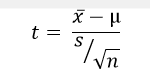
Note: t-test works well when the number of samples are less than 30.
Step 5- You can compare P-value with level of significance OR Z-score with Critical Value.(use any one)
Calculate Z-Score using step 4 i.e using test statistics
Once the Z-score has been calculated, find the P-value using Z-score with the help of Z-table
P-value
The P value is the probability of finding the observed OR more extreme results when the null hypothesis (H0) of a study question is true. In case, the P-value is more than the alpha value (level of significance), the null hypothesis is failed to be rejected else the null hypothesis is rejected.
- Left-tailed z-test:
p-value = Φ(Zscore) - Right-tailed z-test:
p-value = 1 - Φ(Zscore) - Two-tailed z-test:
p-value = 2 * Φ(−|Zscore|)
or
p-value = 2 - 2 * Φ(|Zscore|)
Suppose Z-score = 0.554 for two tailed calculated in step 4 and level of significance which is determined in step 3, then using formula p-value = 2 - 2 * Φ(|Zscore|), the p-value will be-
- Φ(|Zscore|) will be 0.7088 (by decomposing 0.5 and 0.05 in z-table)
- Therefore p-value is 2 – 2(0.7088) = 0.5824
- Then compare the p-value and level of significance (alpha). Here p-value>alpha. Hence failed to reject null hypothesis.
Step 6 – Calculate Critical value using level of significance
Critical values in hypothesis testing depend upon a test statistic, which is specific to the type of test such as z-test, t-test etc. and the significance level (alpha), which defines the sensitivity of the test.
Example 1] If statistics test is z-test and level of significance is 0.05. And it is upper tailed test, then critical value will be-
Confidence Interval = 1 – level of significance = 1 – 0.05 = 0.95
For 0.95 ,critical value in +ve z-table is 1.645 (i.e 1.6 and .04 +5)
Example 2] If statistics test is z-test and level of significance is 0.025. And it is lower tailed test, then critical value will be-
level of significance = 0.025
For 0.025 ,critical value in –ve z-table is -1.96 (i.e -1.9 and .06)
Example 3] If statistics test is z-test and level of significance is 0.01. And it is two tailed test, then critical value will be-
Confidence Interval = 1 – level of significance = 1 – 0.01 = 0.99
For (1+0.99)/2 i.e 0.995 ,critical value in +ve z-table is 2.576 (i.e 2.5 and .07)
|
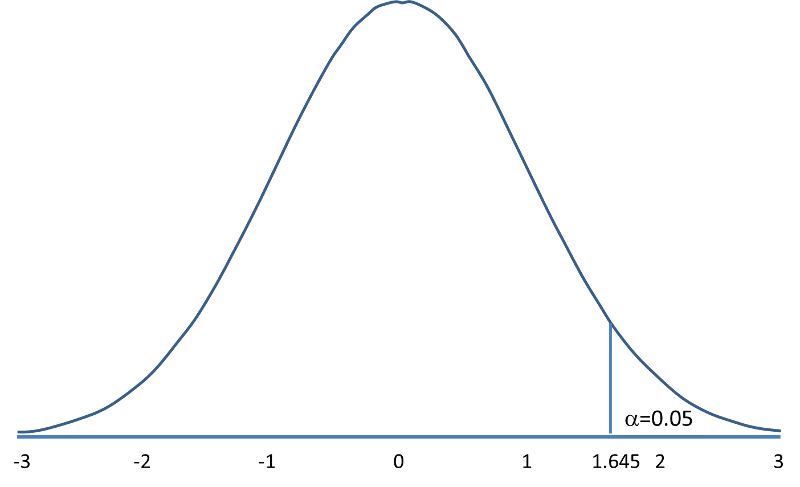
Rejection Region for Upper-Tailed Z Test (H1: μ > μ0 ) with α=0.05 The decision rule is: Reject H0 if Z > 1.645. |
|
||||||||||||||||||
|
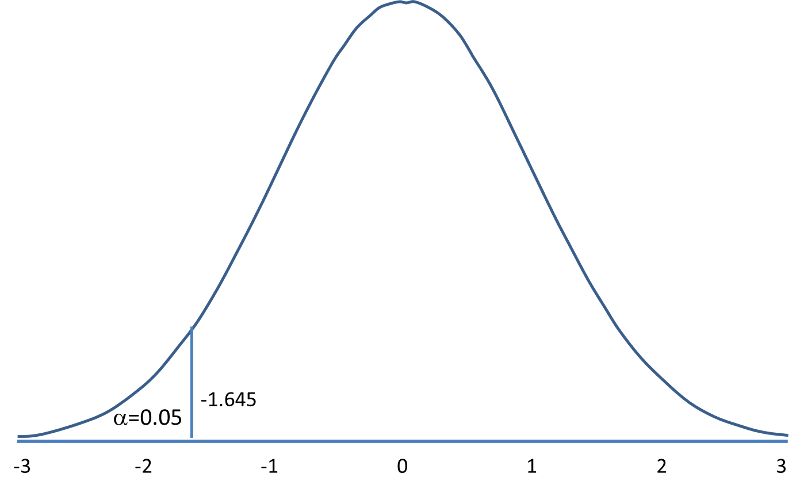
Rejection Region for Lower-Tailed Z Test (H1: μ < μ0 ) with α =0.05 The decision rule is: Reject H0 if Z < 1.645. |
|
||||||||||||||||||
|
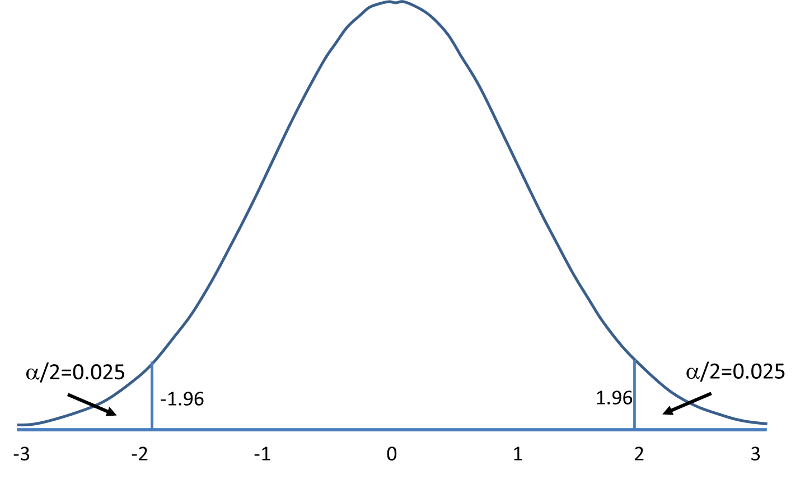
Rejection Region for Two-Tailed Z Test (H1: μ ≠ μ 0 ) with α =0.05 The decision rule is: Reject H0 if Z < -1.960 or if Z > 1.960. |
|
||||||||||||||||||
Step 6 – Compare critical-value with Z-score
If p-value is greater than level of significance Or if Z-score less than Critical value we failed to reject the Null Hypothesis. This region is also called as Non-rejection region.
If p-value is less than level of significance Or if Z-score greater than Critical value we reject the Null Hypothesis. This region is also called as Rejection region.

- A random sample of 50 items gives the mean 6.2 and S.D.10.24 .Can it be regarded as drawn from a population with mean 5.4 at 5% level of significance.
Ans-

Using Z-score and critical value-
In Step 2: Select an appropriate test statistic and calculate the z- score
As n=50(>30), we are going to select z-test to calculate z-score
In Step 3 &4 : Determine the alpha (level of significance) and Obtain the critical value
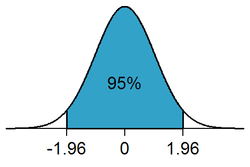
For a 5% level of significance, the critical value will be ±1.96.
It is calculated by using the formula A=(1+Confidence Level)/2.
Substituting the values,
⇒A=(1+0.95)/2
Adding and dividing by 2,
⇒A=1.95/2=0.975
Looking for this value in the normal distribution table(z-table) given above, we can see that this value lies on the row containing 1.9 and column containing 0.06. Adding the two values,
⇒1.9+0.06=1.96
Step 5: Compare z-score and critical value.
As we see, 0.554 < 1.96, which means our z-score lies within the acceptance region. This means our null hypothesis retains. Fail to reject Ho and Reject H1.
Type 1 Error & Type 2 Error in hypothesis testing
No hypothesis test is 100% correct. Because the test is based on probabilities, there is always a chance of making an incorrect conclusion. When you do a hypothesis test, two types of errors are possible: type I and type II. The risks of these two errors are inversely related and determined by the level of significance and the power for the test. Therefore, you should determine which error has more severe consequences for your situation before you define their risks.
Type I error:
When the null hypothesis is true and you reject it, you make a type I error. The probability of making a type I error is α, which is the level of significance you set for your hypothesis test. An α of 0.05 indicates that you are willing to accept a 5% chance that you are wrong when you reject the null hypothesis. To lower this risk, you must use a lower value for α. However, using a lower value for alpha means that you will be less likely to detect a true difference if one really exists.
Type II error:
When the null hypothesis is false and you fail to reject it, you make a type II error. The probability of making a type II error is β, which depends on the power of the test. You can decrease your risk of committing a type II error by ensuring your test has enough power. You can do this by ensuring your sample size is large enough to detect a practical difference when one truly exists. The probability of rejecting the null hypothesis when it is false is equal to 1–β. This value is the power of the test.
Avoiding Type-I Error:
Minimize the significance level (α) of Hypothesis Test: since we choose the significance level. However, lowering the significance level may lead to a situation wherein the results of the hypothesis test may not capture the true parameter or the true difference of the test.
Avoiding Type-II Error:
a. Increase the sample size
b. Increase the significance level of Hypothesis Test.
Power: Usually known as the probability of correctly accepting the null hypothesis. 1-beta is called power of the analysis.