Natural Language Processing - Overview - Text Representation Tutorial
I] What is feature extraction from text?
Feature extraction refers to the process of transforming raw data into numerical features that can be processed while preserving the information in the original data set.
Ii] why do we need it?
Because machines only accept numerical values.
Iii] Why is it difficult?
Image can converted to numeric using a matrix, audio can be converted to numeric using amplitude.
The sentence is difficult to convert.
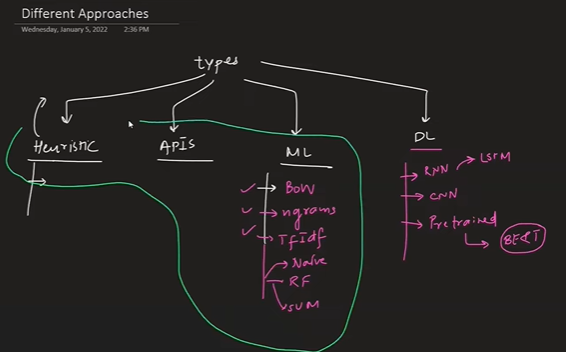
The technique used to convert it into numeric is
- One hot encoding
- Bag of words
- Ngrams
- TFIDF
- Custom feature
- Word2Vec { embeddings- deep learning technique}
Common Terms-
Corpus – a collection or concatenate of all text in the dataset column or df[‘review’] all review combined
Vocabulary – unique word in the corpus
Document – one individual review is one document
Word – each word used in the document is the word
- One hot encoding
One hot encoding can be defined as the essential process of converting the categorical data variables to be provided to machine and deep learning algorithms which in turn improve predictions as well as classification accuracy of a model

Pros – Intuitive, easy implementation
Cons – Sparsity, No fixed size, Out Of Vocabulary, No capturing of semantic
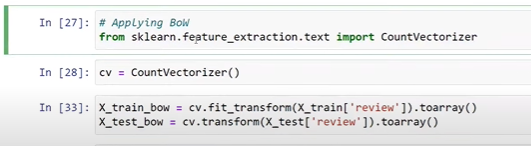
- Bags Of Words – A bag of words is a representation of text that describes the occurrence of words within a document.

From sklearn.feature_extraction.text import CountVectorizer
Cv = CountVectorizer()
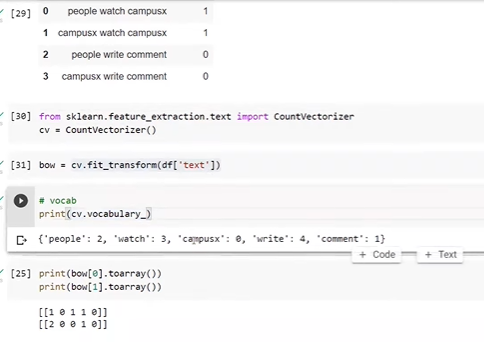
Out Of vocabulary word is solved here-(i.e of and ) -


Advantages- Simple, intuitive, fixed size, slightly capture of semantic better than OHE
Disadvantages – Sparsity, Out of vocabulary, Ordering
- N-grams OR Bags of n-grams
In this vocabulary of word is a combination of multiple words. For bi-gram, it is a combination of 2 words, n-gram is a combination of n words. to get the proper ordering.
Bi-gram -

In countVectorizer there is parameter ngram_range for unigram is (1,1), for bigram is (2,2)
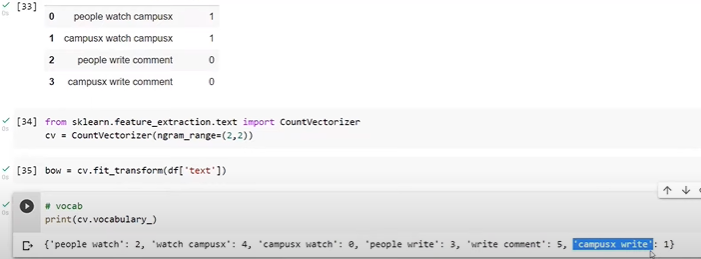
(1,2) – unigram and bigram both

Advantage- able to capture semantic of the sentence, easy implement
Disadvantage –slows down the algo, Out of vocabulary
- TFIDF – (Term frequency, Inverse Document Frequency) it will assign different different value to different word.
In this, if one word is repeated in that document than other remaining word. Then that word will high frequency than other word. (i.e weightage)
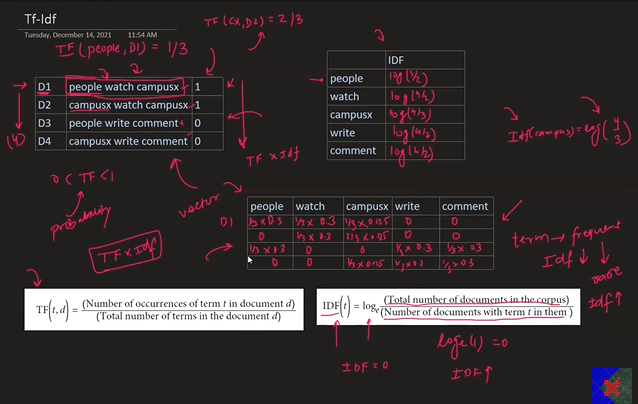

Advantage – Information Retrieval
Disadvantage – Sparsity, Out of Vocabulary, Dimension, Does not capture Semantic relationship
- Custom Features
Word Embeddings – In NLP, word embedding is a term used for the representation of words for text analysis, typically in the form of a real-valued vector that encodes the meaning of the word such that the words that are closer in the vector space are expected to be similar in meaning.
Word2Vec
It is a word embedding technique that converts words to a collection of numbers. The Word2Vec model is used to extract the notion of relatedness across words or products such as semantic relatedness, synonym detection, concept categorization, selectional preferences, and analogy. A Word2Vec model learns meaningful relations and encodes the relatedness into vector similarity.
Import genism
From gensim.models import Word2Vec, KeyedVectors





Type Of Word2Vec
- CBow – Continuous bag of word
- Skip-gram
Both are shallow neural networks.
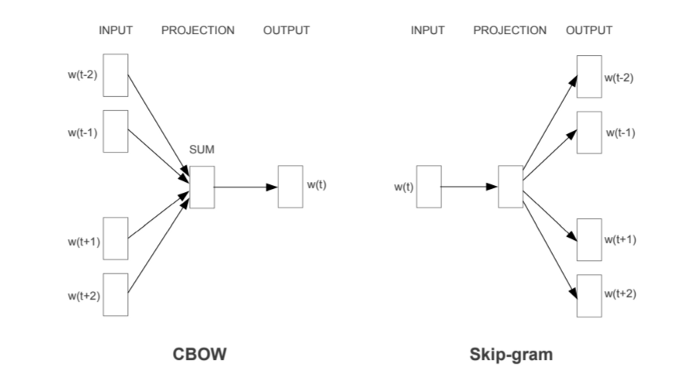
In the CBOW model, the distributed representations of context (or surrounding words) are combined to predict the word in the middle. While in the Skip-gram model, the distributed representation of the input word is used to predict the context.
Text Classification
Types Of Text Classification
1] Binary (eg. spam or not spam in email
2] Multiclass (eg. Category of news i.e sport, politics, entertainment, etc)
3] Multilevel ( e.g one news can come into multiple categories such as sport and entertainment etc)
Application-
1] Email Spam classification
2] Customer Support ( whether is chat is for sales or support)
3] Sentiment Analysis
4] Language Detection (hindi , Marathi or English etc)
5] Fake news detection
Using BOW and n-grams
Bags Of Words-
n-gram-

Using TFIDF-

Using Word2Vec-
Making word2vec of the sentence using average word2vec