Natural Language Processing - Overview - Text Preprocessing Tutorial
Basic-
- Lowercasing – python is case sensitive. Therefore, “Basic” and “basic” both are different.
Use df[‘review’].lower() to convert to lowercase.
- Remove Html Tag – use regex to remove html tag. As html tag is not required
- Remove URL – use regex to remove URL. As url is not required
- Remove Punctuation –i.e !@#$%....etc
- Chat word treatment – such asap(as soon as possible), fyi(for your information), lmao, lol(lot of love), gn(good night),etc
There is dictionary on github of shorthand. Through which you can convert it to fullhand.
- Spelling Correction – you can use textblob or any other library to correct spelling.
- Removing Stop word – stop word are used for statement formation, but it does not contribute to statement meaning. eg- a, the, of, are, my .
Stop word are not removed in POS tagging,
From nltk.corpus import stopwords
Stopwords.words(‘english’) – [I,me,my,and ,the…]
Create function to remove stopwords and apply it to dataframe.
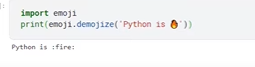
- Handling Emojis – use below function

There is module in python named emoji. That will convert emoji to text.
Import emoji
Print(emoji.demojize(‘python is’))
- Tokenization
1] sentence tokenization – it will divide paragraph based on sentence. Using full stop.
2] word tokenization – it will divide paragraph based on word
Hadoop developer for multiple initiatives. Develop Big Data Strategy and Roadmap for the Enterprise
Sentence_tokenization = [‘Hadoop developer for multiple initiatives’, ‘Develop Big Data Strategy and Roadmap for the Enterprise’]
word_tokenization = [‘Hadoop’, ‘developer’, ‘for’, ‘multiple’, ‘initiatives’, ‘Develop’, ‘Big’, ‘Data’, ‘Strategy’, ‘and’, ‘Roadmap’, ‘for’, ‘the’, ‘Enterprise’]
using the split(), take space for word and full stop for sentence.
Or regular expression
Or use NLTK library(Recommended)
From nltk.tokenize import word_tokenize,, sent_tokenize

Or Spacy (best recommended)
Import spacy
Nlp = spacy.load(‘en_core_web_sm’)

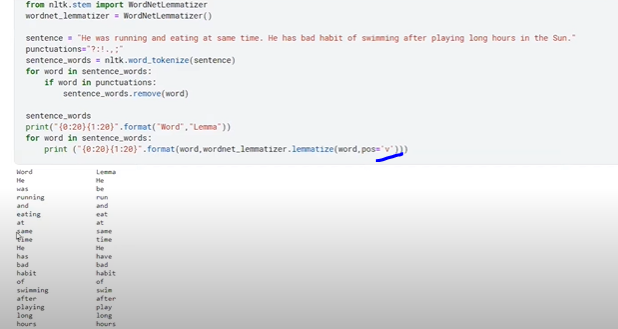
- Stemming
Stemming convert inflection word to root word
For example-
Dancing, dance, danced
Then stemming word id – danc

Lemmatization – stemming will provide root word(sometime meaningless). Lemmatization will provide meaningful English word.
Stemming is fast, lemmatization is slow.
Advance- Part of speech tagging, chunking, parsing, co-reference resolution