Machine Learning - Supervised Learning - Linear Regression [Regression] Tutorial
- Linear Regression [Regression]
Linear regression algorithm shows a linear relationship between a dependent (y) and one or more independent (y) variables, hence called as linear regression.
Three types of linear regression
- Simple Linear Regression
- Multiple Linear Regression
- Polynomial Linear Regression
- Simple Linear Regression
1 input column & 1 output column
Simple linear regression is a regression model that estimates the relationship between one independent variable and one dependent variable using a straight line. Both variables should be quantitative
Equation-
y = mx +b
m – Slope Or Coefficient of x
b – Intercept
Geometric Intuition – To find m and b
Example – cgpa(x) & package(y)
If cgpa is high, then the package is also high
When working with linear regression our main goal is to find the best-fit line, which means the error between predicted value and actual value should be minimized.
For the best-fit line, we need to calculate the best value of m and b. To calculate this we use the cost function.
Two different solutions to find the perfect m and b-
I] Closed Form Solution – OLS(Ordinary Least Square)( used in lower dimension)
An equation is said to be a closed-form solution if it solves a given problem in terms of functions and mathematical operations from a given generally-accepted set(it doesn’t used differentiation and integration). For example, an infinite sum (summation) would generally not be considered closed-form. However, the choice of what to call closed-form and what not is rather arbitrary since a new "closed-form" function could simply be defined in terms of the infinite sum.

OLS(Ordinary Least Square)
The ordinary least squares (OLS) method is a linear regression technique that is used to estimate the unknown parameters (m and b) in a model. The method relies on minimizing the sum of squared residuals between the actual and predicted values to find the best-fit line. The residual can be defined as the difference between the actual value and the predicted value.
And, the calculus method for minimizing the sum of squares residuals is to take the partial derivative of the cost function(E) with respect to the coefficients of determination (m,b). Then set the partial derivatives equal to zero and solve for each of the coefficients using the concept of maxima and minima - https://www.cuemath.com/calculus/maxima-and-minima/
The OLS method is also known as the least squares method for regression or linear regression.
b= Y-mX
m= i=1n(Xi-X)Yi-Yi=1nXi-X2
Gradient Descent Is faster than OLS. Gradient descent has less time complexity than OLS. OLS is only used for small datasets, Gradient descent is used for large datasets.
Gradient descent has a time complexity of O(ndk), where d is the number of features, and n Is the number of rows. So, when d and n and large, it is better to use gradient descent.
II] Non-Closed Form Solution – Gradient Descent(used in higher dimension) – SGD Regressor
Gradient Descent –
Hyperparameter – Learning Rate, epoch

Gradient Descent (also often called steepest descent) is a first-order iterative optimization algorithm used for finding local minima of a differentiable function OR minimizing the cost function (i.e. errors between actual and expected results).
It is also used to train neural networks. It is based on a convex function. It is the backbone of deep learning.
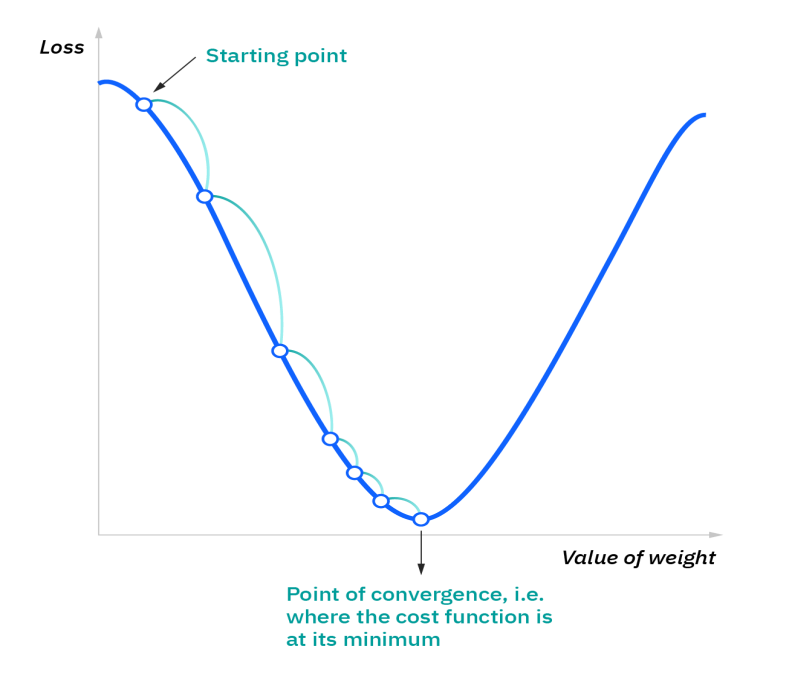
The starting point is just an arbitrary point for us to evaluate the performance. From that starting point, we will find the derivative (or slope), and from there, we can use a tangent line to observe the steepness of the slope(it will give the direction). The slope will inform the updates to the parameters—i.e. the weights and bias. The slope at the starting point will be steeper, but as new parameters are generated, the steepness should gradually reduce because of the learning rate until it reaches the lowest point on the curve, known as the point of convergence.
The goal of gradient descent is to minimize the cost function or the error between predicted and actual y. In order to do this, it requires two data points—a direction and a learning rate. These factors determine the partial derivative calculations of future iterations, allowing it to gradually arrive at the local or global minimum (i.e. point of convergence)
- The learning rate (also referred to as step size when it is multiplied by slope or the alpha) is the size of the steps that are taken to reach the minimum. This is typically a small value(0.01), and it is evaluated and updated based on the behavior of the cost function. High learning rates result in larger steps but risk overshooting the minimum. Conversely, a low learning rate has small step sizes. While it has the advantage of more precision, the number of iterations compromises overall efficiency as this takes more time and computations to reach the minimum.
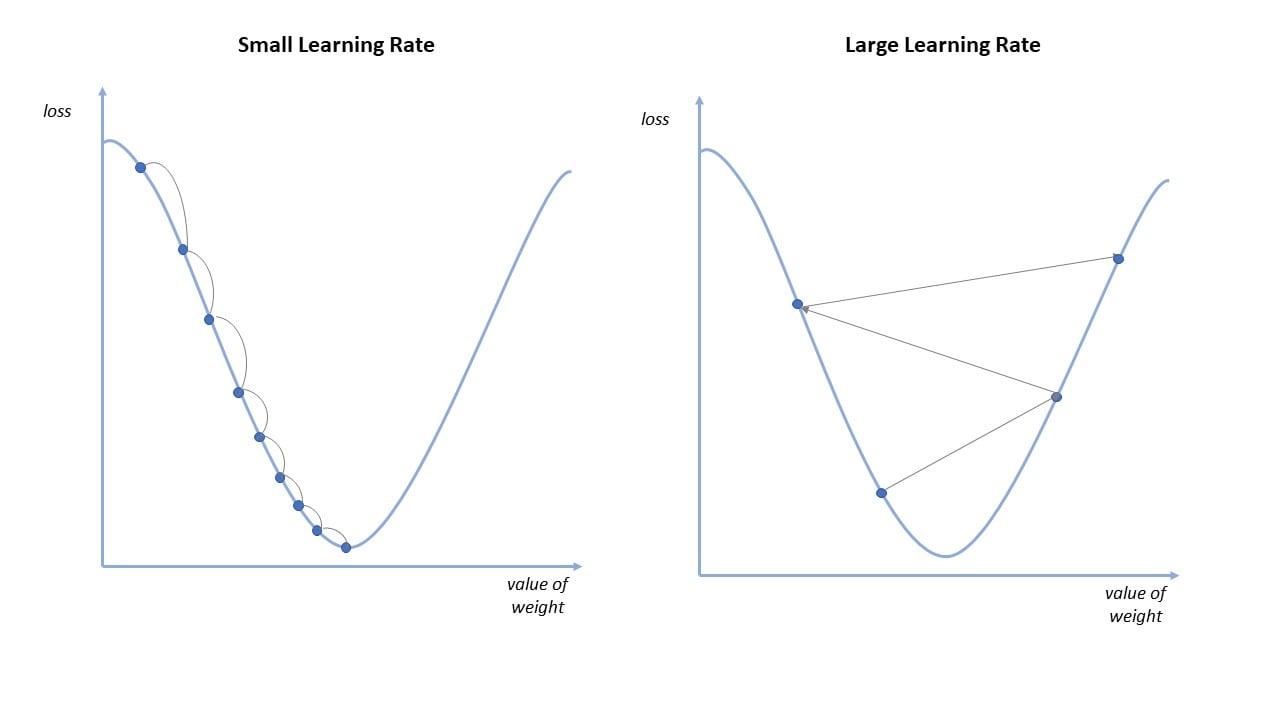
- Direction is decided using slope. If the slope is negative, it will move toward a positive direction(i.e. new = bold – (learning rate * Slope)).
If bold = -10,learning rate=0.1 and slope = -4.
Then bnew = -9.6 , which means it is moving toward the point of convergence.
We will again take bnew as bold, the slope will also increase as it moves toward the point of convergence(from -4 to -3) i.e
If bold = -9.6,learning rate=0.1 and slope = -3.
Then bnew = -9.3 , which means it is again moving toward the point of convergence.
It will keep moving till no. of the epoch ended. It will always come to the point of convergence anyhow
The same happens in the case of the coefficient.
How to calculate slope? The slope is calculated by differentiating the cost function with respect to m(coef) and b(intercept)
- The cost (or loss) function measures the difference, or error, between actual y and predicted y at its current position. This improves the machine learning model's efficacy by providing feedback to the model so that it can adjust the parameters to minimize the error and find the local or global minimum. It continuously iterates, moving along the direction of the steepest descent (or the negative gradient) until the cost function is close to or at zero. At this point, the model will stop learning. Additionally, while the terms, cost function and loss function, are considered synonymous, there is a slight difference between them. It’s worth noting that a loss function refers to the error of one training example, while a cost function calculates the average error across an entire training set.
- Epochs tell us the number of times the model will be trained in forwarding and backward passes.
When to stop iteration in gradient?
- If bnew – bold <0.001, then iteration needs to be stopped, as the graph after that become stable(no improvement).
- Limit the iteration i.e. epoch, after a certain epoch graph becomes stable.
Types of Gradient Descent-
- Batch Gradient Descent
Batch gradient descent (BGD) sums the error for each point in the training set and updates the model after evaluating all training examples.
Dataset-wise update ( 1 update per epoch)
But if the number of training examples is large, then batch gradient descent is computationally very expensive. Hence batch gradient descent is not preferred for large data. Instead, we prefer to use stochastic gradient descent or mini-batch gradient descent.
When to use Batch GD?
1] Small Data
2] Convex function(only local minima)
- Stochastic Gradient Descent
Hyperparameter – max_iter is epoch default 1000 , learning_rate=’constant’, eta0=0.01
loss:squared loss, penalty : l2,l1 , tolerance(if want to stop iteration at middle), shuffle, random_state
Stochastic gradient descent (SGD) runs a training epoch for each example within the dataset and it updates each training example's parameters one at a time. Hence this is quite faster than batch gradient descent. But again, when the number of training examples is large, even then it processes only one example which can be additional overhead for the system as the number of iterations will be quite large.
Randomly Row wise update ( n update per epoch), where n=no. of row
Advantage – Faster conversion (required less number of epochs), Not required to load whole data at once.
Although Stochastic use less number of epoch than batch, to reach a point of convergence. But if there is the same number of epochs in both batch and stochastics, then the batch will take less time than stochastics.
For 100 epochs, the batch will take 100 updates. In stochastic, it will take 100 * no. of row updates.
Disadvantage – Not steady solution(running stochastics descent on same data multiple time will provide different output every time) (not precise)(this problem can be solved by learning schedules, which is used to vary learning rate)

In learning schedules, as the number of epoch increase learning rate will get reduced. Which results in decreased fluctuation and becomes stable when it comes near to point of convergence.
When to use Stochastic GD?
1] Big Data
2] Non Convex function( global minima,local minima)
In convex function, there is global minima, no local minima
- Mini Batch Gradient Descent (use SGD with partial fit to implement it using sci-kit learn, in deep learning there are keras)
Batch wise Update (b update per epoch), where b = no. of batch
This is a type of gradient descent that works faster than both batch gradient descent and stochastic gradient descent. Here no. of iteration is equal to the no. of the batch. So even if the number of training examples is large, then all training example is divided into multiple batches. It sums the error for each point in the batch and updates the model after evaluating each batch. Thus, it works for larger training examples, and that too with a lesser number of iterations.
Batch gradient descent

Batch gradient descent is fast as compared to stochastic for the same no. of epoch.
e.g. Batch will take 1 sec to complete, while stochastic will take 10 sec to complete for the same no. of epoch.
BUT
For same no. of epoch Stochastic will reach a faster point of convergence than batch.
e.g for 10 epochs, stochastic will reach an accuracy of 98%, while batch will reach an accuracy of 60%.

Stochastic GD-
Advantage- help the algorithm to move out of local minima and converge toward global minima because of spikiness.
Disadvantage – Will not reach the exact solution, it will reach an approximate solution.
Vectorization-
In batch we have not used a loop as we have used in stochastic, instead, we used the dot product of datapoint, which is a vectorization.
The dot product is the smart replacement of a loop, which is faster than a loop.
Hence, batch GD is faster than stochastic GD

The disadvantage of vectorization-
But if there is 10cr data in the dataset then it will not work, because you have to load 10 cr data at a time in memory(RAM). It is faster for small data.
Mini Batch Gradient Descent-

No. of batch = No of datapoint/batch_size
Fast (time)
Batch GD > mini Batch GD > Stochastic GD
Convergence
Batch GD < mini Batch GD < Stochastic GD