Machine Learning - Ensemble Learning - Advanced Ensemble Techniques Tutorial
- Stacking
Stacking (stacked generalization) is an ensemble technique that uses meta-learning for generating predictions. Meta model provide the final prediction based on the prediction from submodel or base model. This final model is said to be stacked on top of the others, hence it is named stacking.
- In this, original data is splitted into train and test.
- Then train is splitted into n fold, n fold data is again splitted into (n-1) data part and (1 or nth ) validation data part.
- First we need to train meta model using base model. Then again train base model.
Suppose we have case, where n is 4 and we have 3 model LR, DT and KNN
Lets take LR model first
Then (n-1) data part is fitted into base models, and then will calculate the prediction of (1 or nth) data part.
i.e first 3 part of data is fitted into LR model, and 4th data are predicted.
Next we will fit data on 1st,2nd and 4th part of data, and will make prediction on 3rd part.
Next again we will fit data on 1st,3rd and 4th part of data, and will make prediction on 2nd part.
Next we will fit data on 2nd , 3rd and 4th part of data, and will make prediction on 1st part.
Such that we will get prediction on all part of data.
Now step iii is only done for LR model, we need to perform same step for remaining model i.e DT and KNN.
Such that we get new column LR_pred, DT_pred and KNN_pred. We can use this column as input and actual target column as output.
- Based on the data obtain on step iii. we will fit/train that data in meta model.
Let say meta model is RF .in which LR_pred, DT_pred and KNN_pred column is input column and actual target column as output.
Such that training data set get trained on meta model.
But training on base model is still remaining.which will see in step v.
- Forget all the above process, now train the training data using LR, then again train same data using DT, and then KNN.
Now we have trained all the 4 model (3 base model –LR,DT, KNN and 1 meta model - RF).
We can use object of these model to make prediction on Test data


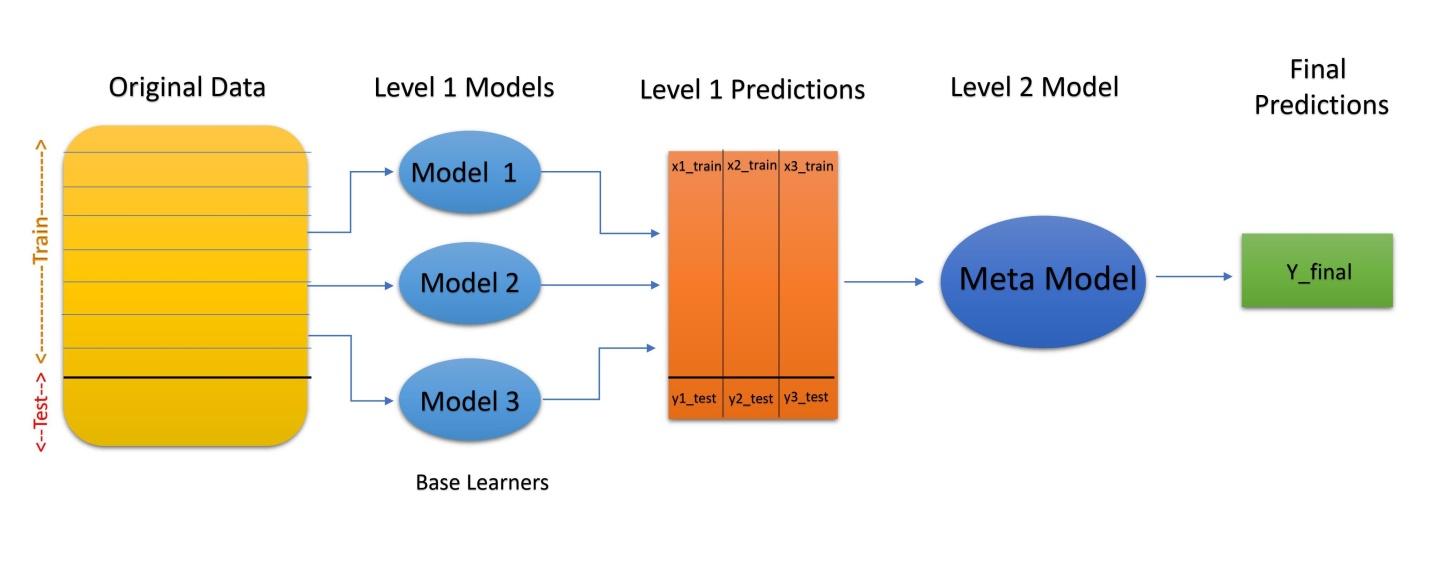
Original Data - The original split is split into n-folds
Base Models - Level 1 individual Models
Level 1 Predictions - Predictions generated by base models on original data
Level 2 Model - Meta-Learner, the model which combines the Level 1 predictions to generate best final prediction
Blending –Stacking using Hold Out method is blending.

- In this, original data is splitted into train and test.(suppose 80:20 ratio)
- Then train is splitted into train and validation part, let say D_train and D_validation. .(suppose 80:20 ratio)
- Suppose we have 3 base model i.e LR, DT and KNN, and meta model as RF
Firstly we will train D_train using LR, and make prediction on D_validation, say the output is LR_pred.
secondly we will train D_train using DT, and make prediction on D_validation, say the output is DT_pred.
Lastly we will train D_train using KNN, and make prediction on D_validation, say the output is KNN_pred.
- Now we will use LR_pred, DT_pred and KNN_pred as input column and actual target column as output to train meta model i.e RF.
- Such that we also train meta model in step iv and we already train all 3 base model on step 3.
- Now we can use all these 4 model for prediction of test dataset, that is splitted in step i.
Stacking – Stacking using K-Fold method stacking only.
Bagging
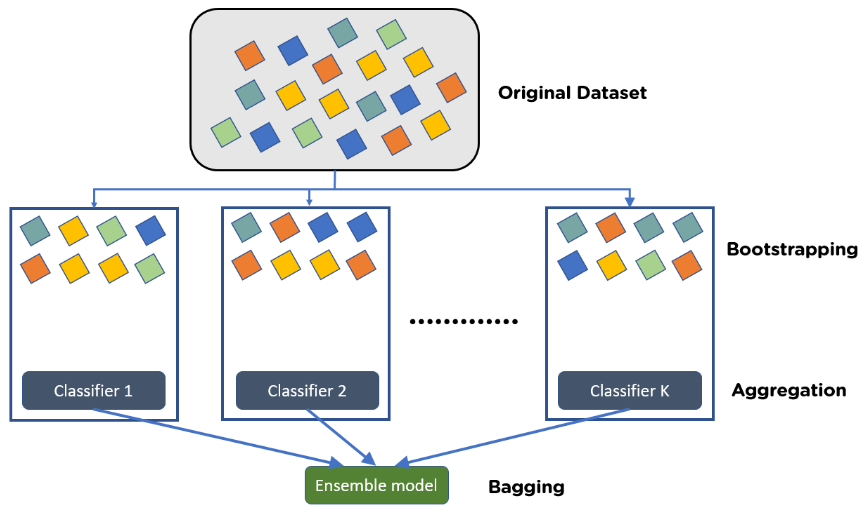
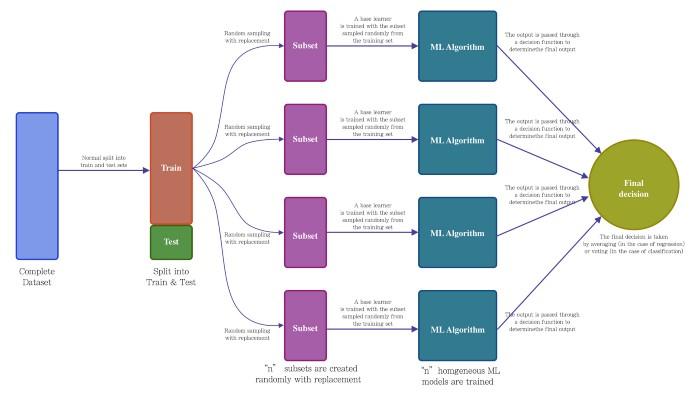
Bagging, also known as bootstrap aggregating ensemble technique, is the aggregation of multiple versions of a predicted model that is achieved using bootstrapping. Bootstrapping is the method of randomly creating samples from original data with replacement (meaning that the individual data points can be chosen more than once) to achieve ramdomness. Each model is trained individually using homogenous machine learning model, and combined using an averaging process to yield a more accurate estimate. The primary focus of bagging is to deal with bias-variance trade-off, reduce variance and to avoid overfitting issue.
If dependent variable is continuous, then we will use BaggingRegression, otherwise we will use BaggingClassification for classification problem. Both are same, only the aggregation method is changed.
In Regression problem, it will calculate mean/average of prediction. While in classification, it will calculate mode in aggregation process.
Advantages of Bagging in Machine Learning
- Bagging minimizes the overfitting of data
- It improves the model’s accuracy
- It deals with higher dimensional data efficiently
Tell the Difference in bagging with decision tree and random forest?
Difference in bagging and random forest is, in bagging- we use homogenous algorithm other than decision tree to create ensemble.(e.g for 3 different model, we can use SVM,SVM,SVM OR LR,LR,LR)
In random forest –we use only decision tree as a homogenous algorithm to create ensemble.
Other difference is in bagging with decision tree- there is tree level sampling (column sampling and row sampling will decided before the tree creation) and in random forest there is node level sampling (column sampling and row sampling will decided at a time of node creation). Hence there will be more randomness in random forest than bagging with decision tree –(see video 93)
Three Types Of Bagging-
i] Pasting- same as bagging , only difference is it is row sampling without replacement.
ii] Ramdom Subspace –It is bagging technique with column sampling with or without replacement, no row sampling only column.
iii] Random Patches - It is bagging technique with both row and column sampling.
OOB score- Out of bag score. It is statistically proven that whenever we do sampling on original data, then only 60-70 % is chosen in sampling because of replacement, other 20-30% data never come out of the bag i.e it remain unseen to the model. So, to use that unseen data for testing and predicting accuracy on it known as OOB score. And this process is called OOB evaluation.
The OOB_score is computed as the number of correctly predicted rows from the out-of-bag sample